向量存储
这个概念性概述为了简化起见,专注于基于文本的索引和检索。 然而,嵌入模型可以是 多模态 的,向量存储也可以用于存储和检索超出文本的各种数据类型。
概览
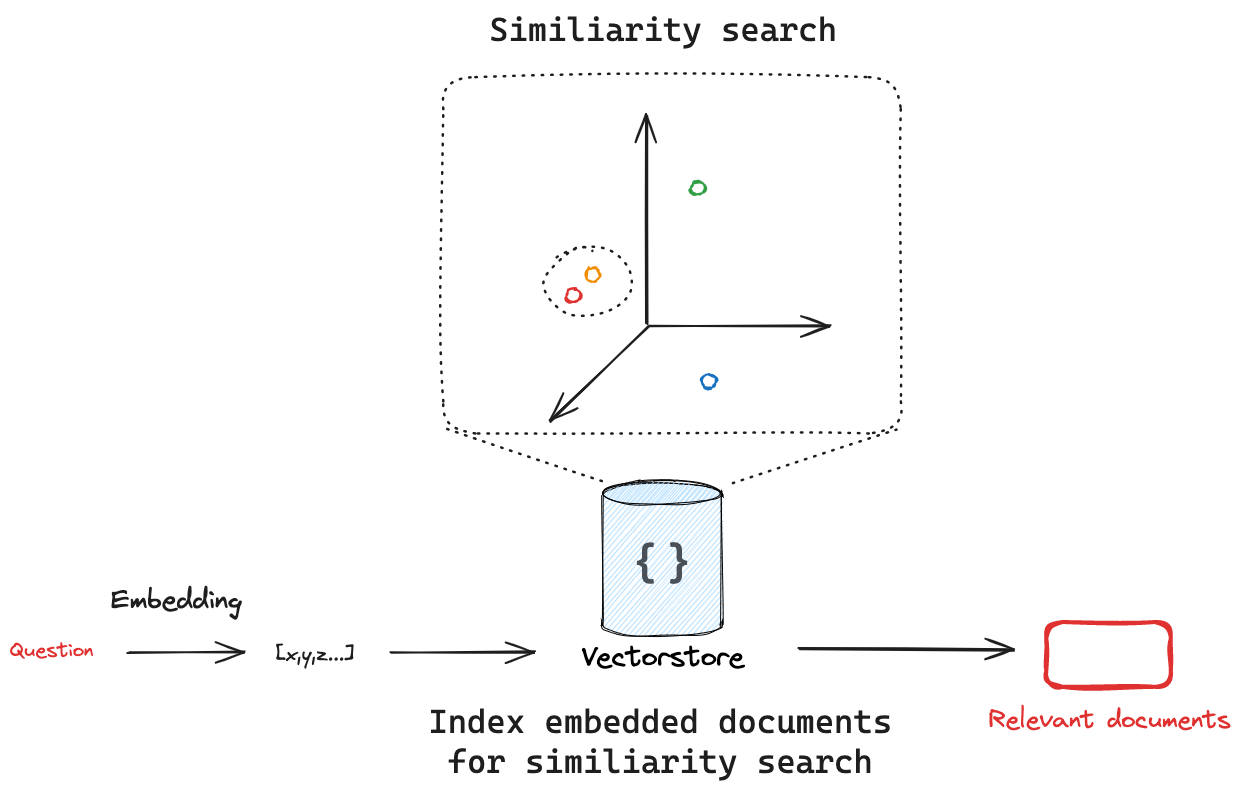
向量存储是一种专门的数据存储方式,能够基于向量表示来实现信息的索引和检索。
这些向量被称为 嵌入,它们捕捉了已嵌入数据的语义含义。
向量存储通常用于在非结构化数据(如文本、图像和音频)中进行搜索,根据语义相似性而非精确的关键词匹配来检索相关信息。
集成
LangChain 拥有大量向量存储集成,使用户能够轻松在不同的向量存储实现之间切换。
界面
LangChain 为向量存储提供了标准接口,使用户能够轻松在不同的向量存储实现之间切换。
该接口包含用于在向量存储中编写、删除和搜索文档的基本方法。
关键方法包括:
add_documents: 将文本列表添加到向量存储中。delete: 从向量存储中删除文档列表。similarity_search: 搜索与给定查询相似的文档。
初始化
LangChain 中的大多数向量在初始化向量存储时都接受一个嵌入模型作为参数。
我们将使用 LangChain 的 InMemoryVectorStore 实现来说明该 API。
from langchain_core.vectorstores import InMemoryVectorStore
# Initialize with an embedding model
vector_store = InMemoryVectorStore(embedding=SomeEmbeddingModel())
添加文档
要添加文档,请使用 add_documents 方法。
此API与 Document 对象列表一起工作。
Document 对象都具有 page_content 和 metadata 属性,使其成为存储非结构化文本和相关元数据的通用方式。
from langchain_core.documents import Document
document_1 = Document(
page_content="I had chocolate chip pancakes and scrambled eggs for breakfast this morning.",
metadata={"source": "tweet"},
)
document_2 = Document(
page_content="The weather forecast for tomorrow is cloudy and overcast, with a high of 62 degrees.",
metadata={"source": "news"},
)
documents = [document_1, document_2]
vector_store.add_documents(documents=documents)
通常情况下,您应该为添加到向量存储中的文档提供ID,这样就不必多次添加相同的文档,而是可以更新现有的文档。
vector_store.add_documents(documents=documents, ids=["doc1", "doc2"])
删除
要删除文档,请使用 delete 方法,该方法接受一个要删除的文档 ID 列表。
vector_store.delete(ids=["doc1"])
搜索
向量存储嵌入并存储已添加的文档。 如果我们传入一个查询,向量存储将嵌入该查询,在嵌入的文档中执行相似性搜索,并返回最相似的文档。 这体现了两个重要概念:首先,必须有一种方法来衡量查询与任意嵌入文档之间的相似性。 其次,必须有一种算法能够高效地在所有嵌入文档中执行这种相似性搜索。
相似性度量
嵌入向量的一个关键优势是,它们可以使用许多简单的数学运算进行比较:
- 余弦相似度: 衡量两个向量之间夹角的余弦值。
- 欧几里得距离: 衡量两点之间的直线距离。
- 点积: 衡量一个向量在另一个向量上的投影。
相似性度量的选择有时可以在初始化向量存储时进行。请参考你所使用的特定向量存储的文档,以了解支持哪些相似性度量。
相似性搜索
给定一个相似性度量来衡量嵌入查询与任何嵌入文档之间的距离,我们需要一种算法来高效地搜索所有嵌入文档,以找到最相似的文档。
有多种方法可以实现这一点。例如,许多向量存储实现了HNSW(分层可导航小世界),这是一种基于图的索引结构,能够实现高效的相似性搜索。
无论底层使用何种搜索算法,LangChain向量存储接口对所有集成都提供了一个similarity_search方法。
该方法将接收搜索查询,创建嵌入,查找相似文档,并将它们作为文档列表返回。
query = "my query"
docs = vectorstore.similarity_search(query)
许多向量存储支持通过 similarity_search 方法传递搜索参数。请参阅您所使用的特定向量存储的文档,以了解支持哪些参数。
例如,Pinecone 支持几个重要的通用概念参数:
许多向量存储支持 方法 k,用于控制返回的文档数量,以及 filter,允许根据元数据过滤文档。
query (str) – Text to look up documents similar to.k (int) – Number of Documents to return. Defaults to 4.filter (dict | None) – Dictionary of argument(s) to filter on metadata
元数据过滤
虽然向量存储实现了一种搜索算法,可以高效地在所有嵌入文档中查找最相似的文档,但许多向量存储还支持基于元数据的过滤。 元数据过滤通过应用特定条件来缩小搜索范围,例如检索来自特定来源或日期范围的文档。这两个概念结合使用效果很好:
- 语义搜索: 直接查询非结构化数据,通常通过嵌入或关键词相似性实现。
- 元数据搜索: 对元数据应用结构化查询,筛选特定文档。
元数据过滤的向量存储支持通常取决于底层向量存储的实现。
以下是使用 Pinecone 的示例,显示我们筛选出所有具有元数据键 source 且值为 tweet 的文档。
vectorstore.similarity_search(
"LangChain provides abstractions to make working with LLMs easy",
k=2,
filter={"source": "tweet"},
)
- 查看 Pinecone 的 文档,了解如何使用元数据进行过滤。
- 查看支持元数据过滤的 LangChain 向量存储集成列表。
高级搜索与检索技术
虽然像HNSW这样的算法在许多情况下为高效的相似性搜索提供了基础,但还可以采用其他技术来提高搜索质量和多样性。
例如,最大边际相关性是一种重新排序算法,用于多样化搜索结果,它在初始相似性搜索之后应用,以确保得到更多样化的结果集。
作为第二个例子,一些向量存储提供内置的混合搜索功能,将关键词和语义相似性搜索结合起来,融合了两种方法的优势。
目前,使用LangChain向量存储执行混合搜索还没有统一的方法,但它通常作为一个关键字参数传递,值为similarity_search。
有关更多详细信息,请参阅此混合搜索操操作指南。
| 名称 | 何时使用 | 描述 |
|---|---|---|
| Hybrid search | When combining keyword-based and semantic similarity. | Hybrid search combines keyword and semantic similarity, marrying the benefits of both approaches. Paper. |
| Maximal Marginal Relevance (MMR) | When needing to diversify search results. | MMR attempts to diversify the results of a search to avoid returning similar and redundant documents. |