评估
评估是衡量您的基于大语言模型(LLM)的应用程序性能和效果的过程。 它涉及将模型的响应结果与一组预定义的标准或基准进行对比,以确保其达到预期的质量标准并实现既定目标。 这一过程对于构建可靠的应用程序至关重要。
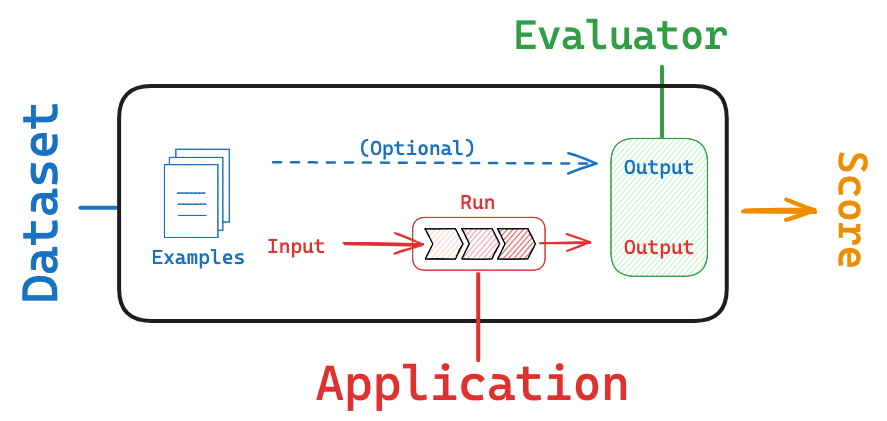
LangSmith 以几种方式帮助此过程:
- 通过其追踪和注释功能,使其更容易创建和整理数据集。
- 它提供了一个评估框架,帮助你定义指标,并将你的应用程序针对数据集进行运行。
- 它允许你跟踪随时间变化的结果,并自动按计划或作为 CI/Code 流程的一部分运行你的评估器。
要了解更多信息,请查看 此 LangSmith 指南。