构建检索增强生成(RAG)应用:第一部分
大型语言模型(LLM)最强大的应用之一是复杂的问答(Q&A)聊天机器人。这些应用能够回答关于特定源信息的问题。这些应用使用一种称为检索增强生成(Retrieval Augmented Generation),或 RAG 的技术。
这是一个多部分教程:
本教程将展示如何基于文本数据源构建一个简单的问答应用。在过程中,我们将介绍典型的问答架构,并指出更多高级问答技术的额外资源。我们还将了解 LangSmith 如何帮助我们追踪和理解应用程序。随着应用程序复杂性的增加,LangSmith 的作用将愈发显著。
如果您已经熟悉基本的检索,您可能还对 这个 不同检索技术的高级概述 感兴趣。
注意: 在这里我们专注于非结构化数据的问答。如果您对结构化数据上的RAG感兴趣,请查看我们关于在 SQL数据上进行问答 的教程。
概览
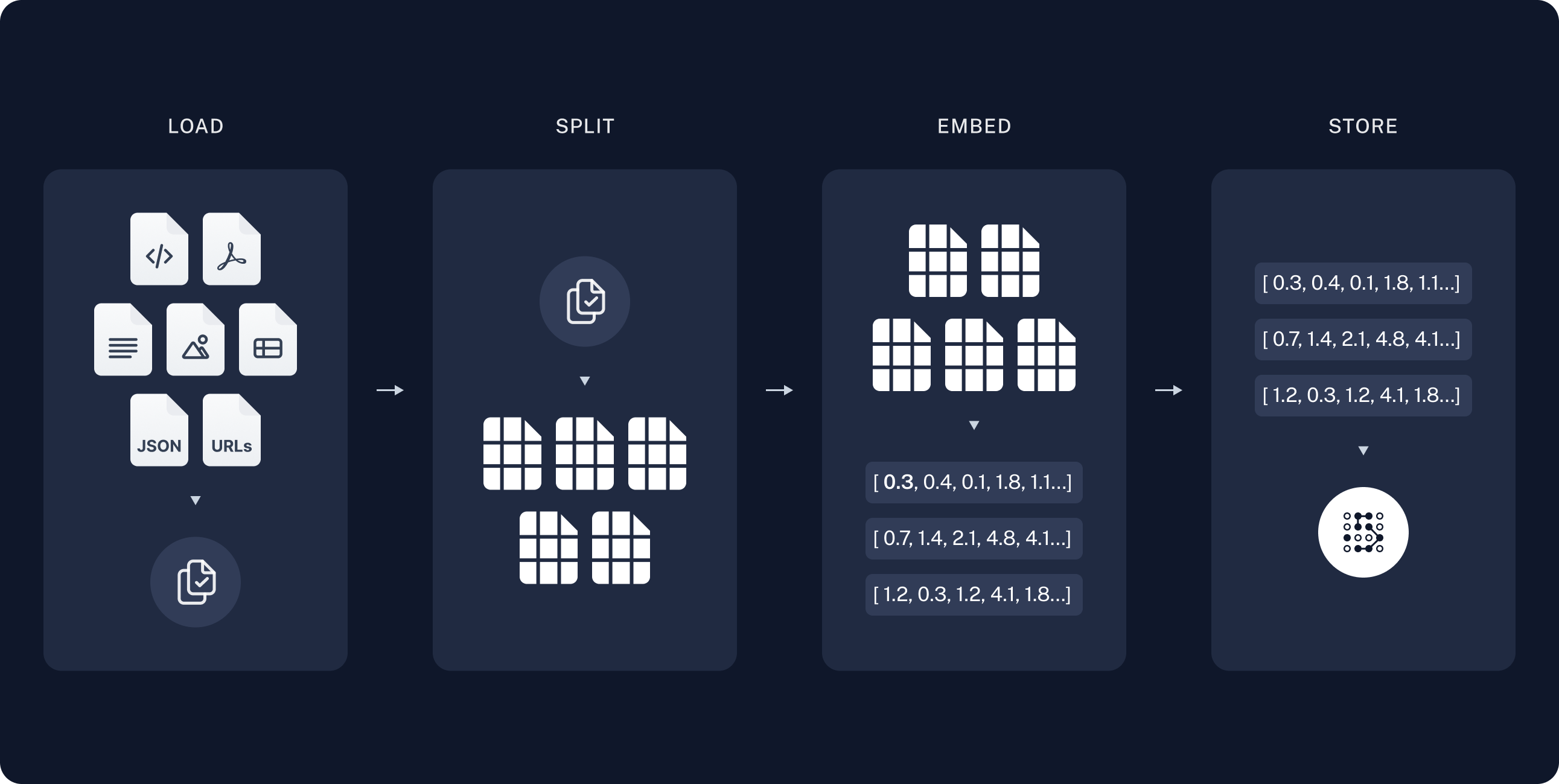
一个典型的RAG应用包含两个主要组件:
索引: 用于从源数据中获取数据并进行索引的管道。 这通常在离线状态下进行。
检索与生成: 实际的RAG链,它在运行时接收用户查询,从索引中检索相关数据,然后将这些数据传递给模型。
注意:本教程的索引部分将主要遵循语义搜索教程。
从原始数据到答案最常见的完整流程是:
索引
- 加载: 首先我们需要加载我们的数据。这可以通过 文档加载器 完成。
- 拆分: 文本拆分器 将大段
Documents拆分为较小的块。这在索引数据和将其传递给模型时都非常有用,因为大块内容更难搜索,且无法放入模型有限的上下文窗口中。 - 存储: 我们需要一个地方来存储和索引我们的文本分块,以便以后可以进行搜索。这通常通过使用 向量存储 和 嵌入模型 来实现。
检索与生成
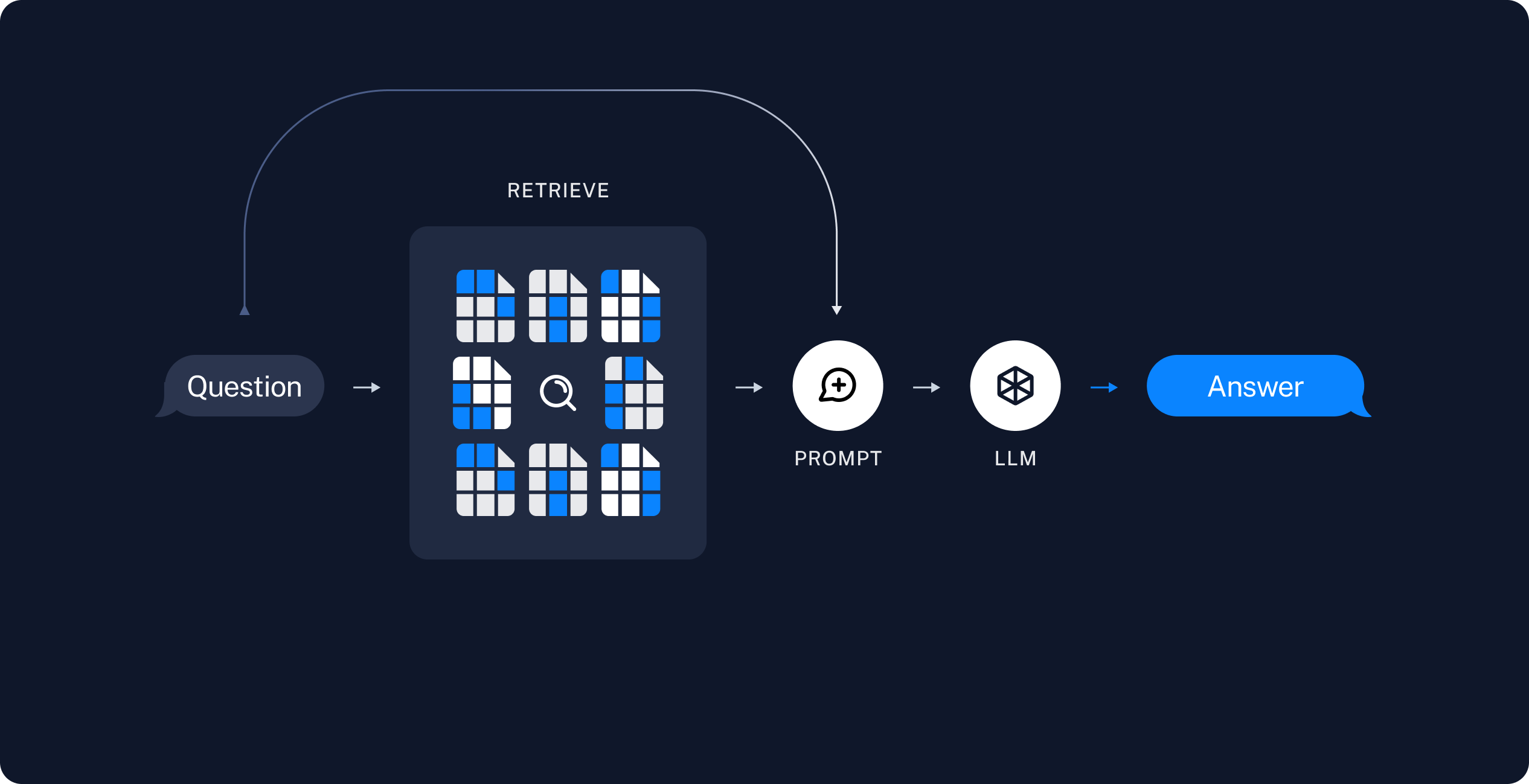
数据索引完成后,我们将使用 LangGraph 作为编排框架来实现检索和生成步骤。
设置
Jupyter Notebook
其他教程也最适合在 Jupyter 笔记本 中运行。在交互式环境中学习指南是更好地理解它们的好方法。有关安装说明,请参见 此处。
安装
本教程需要以下 langchain 依赖项:
- Pip
- Conda
%pip install --quiet --upgrade langchain-text-splitters langchain-community langgraph
conda install langchain-text-splitters langchain-community langgraph -c conda-forge
有关详细信息,请参阅我们的 安装指南。
LangSmith
使用 LangChain 构建的许多应用程序都包含多个步骤,以及多次调用大型语言模型。 随着这些应用程序变得越来越复杂,能够检查链或代理内部的具体情况变得至关重要。 实现这一点的最佳方式是使用 LangSmith。
在您通过上方链接注册后,请确保设置您的环境变量以开始记录追踪信息:
export LANGSMITH_TRACING="true"
export LANGSMITH_API_KEY="..."
或者,如果在笔记本中,你可以通过以下方式设置它们:
import getpass
import os
os.environ["LANGSMITH_TRACING"] = "true"
os.environ["LANGSMITH_API_KEY"] = getpass.getpass()
组件
我们需要从 LangChain 的集成套件中选择三个组件。
pip install -qU "langchain[openai]"
import getpass
import os
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter API key for OpenAI: ")
from langchain.chat_models import init_chat_model
llm = init_chat_model("gpt-4o-mini", model_provider="openai")
pip install -qU langchain-openai
import getpass
import os
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter API key for OpenAI: ")
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
pip install -qU langchain-core
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embeddings)
预览
在本指南中,我们将构建一个能够回答网站内容相关问题的应用程序。我们使用的具体网站是Lilian Weng撰写的关于“基于大语言模型的自主代理”的博客文章,该文章允许我们针对文章内容提出问题。
我们可以在约50行代码内创建一个简单的索引管道和RAG链来实现这一点。
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langgraph.graph import START, StateGraph
from typing_extensions import List, TypedDict
# Load and chunk contents of the blog
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)
# Index chunks
_ = vector_store.add_documents(documents=all_splits)
# Define prompt for question-answering
prompt = hub.pull("rlm/rag-prompt")
# Define state for application
class State(TypedDict):
question: str
context: List[Document]
answer: str
# Define application steps
def retrieve(state: State):
retrieved_docs = vector_store.similarity_search(state["question"])
return {"context": retrieved_docs}
def generate(state: State):
docs_content = "\n\n".join(doc.page_content for doc in state["context"])
messages = prompt.invoke({"question": state["question"], "context": docs_content})
response = llm.invoke(messages)
return {"answer": response.content}
# Compile application and test
graph_builder = StateGraph(State).add_sequence([retrieve, generate])
graph_builder.add_edge(START, "retrieve")
graph = graph_builder.compile()
response = graph.invoke({"question": "What is Task Decomposition?"})
print(response["answer"])
Task Decomposition is the process of breaking down a complicated task into smaller, manageable steps to facilitate easier execution and understanding. Techniques like Chain of Thought (CoT) and Tree of Thoughts (ToT) guide models to think step-by-step, allowing them to explore multiple reasoning possibilities. This method enhances performance on complex tasks and provides insight into the model's thinking process.
查看 LangSmith 追踪。
详细操操作指南
让我们逐步分析上面的代码,真正理解其中的原理。
1. 索引
加载文档
我们需要首先加载博客文章的内容。可以使用 DocumentLoaders 来实现,它们是能够从源加载数据并返回 Document 对象列表的对象。
在这种情况下,我们将使用
WebBaseLoader,
它使用 urllib 从网页URL加载HTML,使用 BeautifulSoup 将其解析为文本。我们可以通过向 BeautifulSoup 解析器传递参数来自定义 HTML -> 文本的解析过程,方法是通过 bs_kwargs(参见
BeautifulSoup
文档)。
在这种情况下,只有 class 为“post-content”、“post-title”或“post-header”的 HTML 标签是相关的,因此我们将移除其他所有标签。
import bs4
from langchain_community.document_loaders import WebBaseLoader
# Only keep post title, headers, and content from the full HTML.
bs4_strainer = bs4.SoupStrainer(class_=("post-title", "post-header", "post-content"))
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs={"parse_only": bs4_strainer},
)
docs = loader.load()
assert len(docs) == 1
print(f"Total characters: {len(docs[0].page_content)}")
Total characters: 43131
print(docs[0].page_content[:500])
LLM Powered Autonomous Agents
Date: June 23, 2023 | Estimated Reading Time: 31 min | Author: Lilian Weng
Building agents with LLM (large language model) as its core controller is a cool concept. Several proof-of-concepts demos, such as AutoGPT, GPT-Engineer and BabyAGI, serve as inspiring examples. The potentiality of LLM extends beyond generating well-written copies, stories, essays and programs; it can be framed as a powerful general problem solver.
Agent System Overview#
In
深入探索
DocumentLoader: 从源加载数据的对象,返回 Documents 的列表。
拆分文档
我们加载的文档超过42,000个字符,这对于许多模型的上下文窗口来说太长了。即使对于那些能够将完整文章放入其上下文窗口的模型,模型在非常长的输入中也可能会难以找到信息。
为了解决这个问题,我们将把 Document 拆分为多个块以进行嵌入和向量存储。这将有助于我们在运行时仅检索博客文章中最相关的内容。
与 语义搜索教程 中一样,我们使用 RecursiveCharacterTextSplitter, 它将递归地使用常见的分隔符(如换行符)分割文档, 直到每个块的大小合适为止。这是通用文本用例的推荐文本分割器。
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # chunk size (characters)
chunk_overlap=200, # chunk overlap (characters)
add_start_index=True, # track index in original document
)
all_splits = text_splitter.split_documents(docs)
print(f"Split blog post into {len(all_splits)} sub-documents.")
Split blog post into 66 sub-documents.
深入探索
TextSplitter: 将一列 Document 拆分为较小块的对象。是 DocumentTransformer 的子类。
- 通过阅读操操作指南,了解使用不同方法拆分文本的更多信息
- 代码(py 或 js)
- 科学论文
- 接口: 基础接口的API参考。
DocumentTransformer: 对列表中的 Document 个对象执行转换操作的对象。
存储文档
现在我们需要对66个文本块进行索引,以便在运行时能够对其进行搜索。按照语义搜索教程,我们的方法是将每个文档片段的内容嵌入,并将这些嵌入插入到一个向量存储中。给定一个输入查询后,我们就可以使用向量搜索来检索相关文档。
我们可以使用教程开始时选择的向量存储和嵌入模型,通过一条命令将所有文档切片嵌入并存储。
document_ids = vector_store.add_documents(documents=all_splits)
print(document_ids[:3])
['07c18af6-ad58-479a-bfb1-d508033f9c64', '9000bf8e-1993-446f-8d4d-f4e507ba4b8f', 'ba3b5d14-bed9-4f5f-88be-44c88aedc2e6']
深入探索
Embeddings: 文本嵌入模型的包装器,用于将文本转换为嵌入向量。
VectorStore: 向量数据库的包装器,用于存储和查询嵌入。
这完成了管道的索引部分。此时,我们已经有一个可查询的向量存储,其中包含博客文章的分块内容。给定一个用户问题,我们理想情况下应该能够返回回答该问题的博客文章片段。
2. 检索与生成
现在,我们来编写实际的应用程序逻辑。我们希望创建一个简单的应用程序,该程序接收用户提出的问题,搜索与该问题相关的文档,将检索到的文档和原始问题传递给模型,并返回答案。
在生成过程中,我们将使用教程开始时选择的聊天模型。
我们将使用一个已提交到 LangChain 提示词库的 RAG 提示 (这里)。
from langchain import hub
prompt = hub.pull("rlm/rag-prompt")
example_messages = prompt.invoke(
{"context": "(context goes here)", "question": "(question goes here)"}
).to_messages()
assert len(example_messages) == 1
print(example_messages[0].content)
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: (question goes here)
Context: (context goes here)
Answer:
我们将使用 LangGraph 将检索和生成步骤整合为一个应用程序。这将带来诸多优势:
- 我们可以一次性定义应用程序逻辑,即可自动支持多种调用模式,包括流式处理、异步调用和批量调用。
- 我们通过 LangGraph 平台 实现了简化的部署。
- LangSmith 将自动追踪我们应用程序的各个步骤。
- 我们可以轻松地通过少量代码更改,为我们的应用程序添加关键功能,包括 持久化 和 人工介入审批。
要使用 LangGraph,我们需要定义三件事:
- 我们应用程序的状态;
- 我们应用程序的节点(即应用程序步骤);
- 我们应用程序的“控制流程”(例如,步骤的执行顺序)。
State:
应用程序的 状态 控制着输入到应用程序的数据、步骤之间的数据传输以及应用程序的输出。它通常是一个 TypedDict,但也可以是一个 Pydantic BaseModel。
对于一个简单的RAG应用,我们只需跟踪输入的问题、检索到的上下文以及生成的答案即可:
from langchain_core.documents import Document
from typing_extensions import List, TypedDict
class State(TypedDict):
question: str
context: List[Document]
answer: str
节点(应用步骤)
让我们从一个简单的两步流程开始:检索和生成。
def retrieve(state: State):
retrieved_docs = vector_store.similarity_search(state["question"])
return {"context": retrieved_docs}
def generate(state: State):
docs_content = "\n\n".join(doc.page_content for doc in state["context"])
messages = prompt.invoke({"question": state["question"], "context": docs_content})
response = llm.invoke(messages)
return {"answer": response.content}
我们的检索步骤仅使用输入的问题运行相似性搜索,生成步骤则将检索到的上下文和原始问题格式化为聊天模型的提示。
控制流程
最后,我们将应用程序编译为一个单一的 graph 对象。在此情况下,我们只是将检索和生成步骤连接成一个单一的序列。
from langgraph.graph import START, StateGraph
graph_builder = StateGraph(State).add_sequence([retrieve, generate])
graph_builder.add_edge(START, "retrieve")
graph = graph_builder.compile()
LangGraph 还提供了内置工具,用于可视化应用程序的控制流程:
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))

我需要使用 LangGraph 吗?
LangGraph 并不是构建 RAG 应用所必需的。实际上,我们可以通过调用各个独立组件来实现相同的应用逻辑:
question = "..."
retrieved_docs = vector_store.similarity_search(question)
docs_content = "\n\n".join(doc.page_content for doc in retrieved_docs)
prompt = prompt.invoke({"question": question, "context": docs_content})
answer = llm.invoke(prompt)
LangGraph 的优势包括:
- 支持多种调用模式:如果希望流式输出令牌,或流式输出各个步骤的结果,则需要重写此逻辑;
- 通过 LangSmith 自动支持追踪,以及通过 LangGraph 平台 部署;
- 支持持久化、人机协作及其他功能。
许多用例都需要在对话体验中使用RAG,以便用户可以通过有状态的对话获得基于上下文的答复。正如我们在本教程的第二部分中将看到的,LangGraph对状态的管理和持久化极大地简化了这些应用。
使用
让我们测试一下我们的应用程序!LangGraph 支持多种调用模式,包括同步、异步和流式处理。
Invoke:
result = graph.invoke({"question": "What is Task Decomposition?"})
print(f'Context: {result["context"]}\n\n')
print(f'Answer: {result["answer"]}')
Context: [Document(id='a42dc78b-8f76-472a-9e25-180508af74f3', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 1585}, page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.'), Document(id='c0e45887-d0b0-483d-821a-bb5d8316d51d', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 2192}, page_content='Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.'), Document(id='4cc7f318-35f5-440f-a4a4-145b5f0b918d', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 29630}, page_content='Resources:\n1. Internet access for searches and information gathering.\n2. Long Term memory management.\n3. GPT-3.5 powered Agents for delegation of simple tasks.\n4. File output.\n\nPerformance Evaluation:\n1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.\n2. Constructively self-criticize your big-picture behavior constantly.\n3. Reflect on past decisions and strategies to refine your approach.\n4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.'), Document(id='f621ade4-9b0d-471f-a522-44eb5feeba0c', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 19373}, page_content="(3) Task execution: Expert models execute on the specific tasks and log results.\nInstruction:\n\nWith the input and the inference results, the AI assistant needs to describe the process and results. The previous stages can be formed as - User Input: {{ User Input }}, Task Planning: {{ Tasks }}, Model Selection: {{ Model Assignment }}, Task Execution: {{ Predictions }}. You must first answer the user's request in a straightforward manner. Then describe the task process and show your analysis and model inference results to the user in the first person. If inference results contain a file path, must tell the user the complete file path.")]
Answer: Task decomposition is a technique used to break down complex tasks into smaller, manageable steps, allowing for more efficient problem-solving. This can be achieved through methods like chain of thought prompting or the tree of thoughts approach, which explores multiple reasoning possibilities at each step. It can be initiated through simple prompts, task-specific instructions, or human inputs.
流式步骤:
for step in graph.stream(
{"question": "What is Task Decomposition?"}, stream_mode="updates"
):
print(f"{step}\n\n----------------\n")
{'retrieve': {'context': [Document(id='a42dc78b-8f76-472a-9e25-180508af74f3', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 1585}, page_content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.'), Document(id='c0e45887-d0b0-483d-821a-bb5d8316d51d', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 2192}, page_content='Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.'), Document(id='4cc7f318-35f5-440f-a4a4-145b5f0b918d', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 29630}, page_content='Resources:\n1. Internet access for searches and information gathering.\n2. Long Term memory management.\n3. GPT-3.5 powered Agents for delegation of simple tasks.\n4. File output.\n\nPerformance Evaluation:\n1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.\n2. Constructively self-criticize your big-picture behavior constantly.\n3. Reflect on past decisions and strategies to refine your approach.\n4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.'), Document(id='f621ade4-9b0d-471f-a522-44eb5feeba0c', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 19373}, page_content="(3) Task execution: Expert models execute on the specific tasks and log results.\nInstruction:\n\nWith the input and the inference results, the AI assistant needs to describe the process and results. The previous stages can be formed as - User Input: {{ User Input }}, Task Planning: {{ Tasks }}, Model Selection: {{ Model Assignment }}, Task Execution: {{ Predictions }}. You must first answer the user's request in a straightforward manner. Then describe the task process and show your analysis and model inference results to the user in the first person. If inference results contain a file path, must tell the user the complete file path.")]}}
----------------
{'generate': {'answer': 'Task decomposition is the process of breaking down a complex task into smaller, more manageable steps. This technique, often enhanced by methods like Chain of Thought (CoT) or Tree of Thoughts, allows models to reason through tasks systematically and improves performance by clarifying the thought process. It can be achieved through simple prompts, task-specific instructions, or human inputs.'}}
----------------
流式输出 标记:
for message, metadata in graph.stream(
{"question": "What is Task Decomposition?"}, stream_mode="messages"
):
print(message.content, end="|")
|Task| decomposition| is| the| process| of| breaking| down| complex| tasks| into| smaller|,| more| manageable| steps|.| It| can| be| achieved| through| techniques| like| Chain| of| Thought| (|Co|T|)| prompting|,| which| encourages| the| model| to| think| step| by| step|,| or| through| more| structured| methods| like| the| Tree| of| Thoughts|.| This| approach| not| only| simplifies| task| execution| but| also| provides| insights| into| the| model|'s| reasoning| process|.||
对于异步调用,请使用:
result = await graph.ainvoke(...)
和
async for step in graph.astream(...):
返回来源
请注意,通过将检索到的上下文存储在图的状态中,我们可以在状态的 "context" 字段中恢复模型生成答案的来源。有关返回来源的更多详细信息,请参阅 此指南。
深入探索
聊天模型 接收消息序列并返回一条消息。
自定义提示
如上所示,我们可以从提示词库中加载提示(例如,这个RAG提示)。提示也可以轻松自定义。例如:
from langchain_core.prompts import PromptTemplate
template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Use three sentences maximum and keep the answer as concise as possible.
Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
custom_rag_prompt = PromptTemplate.from_template(template)
查询分析
到目前为止,我们正在使用原始输入查询执行检索。然而,允许模型生成用于检索的查询具有一些优势。例如:
- 除了语义搜索之外,我们还可以加入结构化过滤器(例如:“查找2020年之后的文档。”);
- 该模型能够重写用户查询,将可能包含多个方面或无关语言的查询转化为更有效的搜索查询。
查询分析 使用模型将原始用户输入转换或构建为优化的搜索查询。我们可以轻松地在应用程序中加入查询分析步骤。为了演示目的,让我们向向量存储中的文档添加一些元数据。我们将向文档添加一些(虚构的)部分,以便稍后进行过滤。
total_documents = len(all_splits)
third = total_documents // 3
for i, document in enumerate(all_splits):
if i < third:
document.metadata["section"] = "beginning"
elif i < 2 * third:
document.metadata["section"] = "middle"
else:
document.metadata["section"] = "end"
all_splits[0].metadata
{'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/',
'start_index': 8,
'section': 'beginning'}
我们需要更新向量存储中的文档。我们将使用一个简单的 InMemoryVectorStore,因为我们会用到其中的一些特定功能(例如,元数据过滤)。有关所选向量存储的相关功能,请参阅向量存储 集成文档。
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embeddings)
_ = vector_store.add_documents(all_splits)
接下来,我们定义搜索查询的模式。我们将使用 结构化输出 来实现这一目的。在此,我们定义查询包含一个字符串查询和一个文档部分(可以是“开头”、“中间”或“结尾”),但也可以根据您的需求进行自定义。
from typing import Literal
from typing_extensions import Annotated
class Search(TypedDict):
"""Search query."""
query: Annotated[str, ..., "Search query to run."]
section: Annotated[
Literal["beginning", "middle", "end"],
...,
"Section to query.",
]
最后,我们向 LangGraph 应用程序添加一个步骤,用于从用户的原始输入生成查询:
class State(TypedDict):
question: str
query: Search
context: List[Document]
answer: str
def analyze_query(state: State):
structured_llm = llm.with_structured_output(Search)
query = structured_llm.invoke(state["question"])
return {"query": query}
def retrieve(state: State):
query = state["query"]
retrieved_docs = vector_store.similarity_search(
query["query"],
filter=lambda doc: doc.metadata.get("section") == query["section"],
)
return {"context": retrieved_docs}
def generate(state: State):
docs_content = "\n\n".join(doc.page_content for doc in state["context"])
messages = prompt.invoke({"question": state["question"], "context": docs_content})
response = llm.invoke(messages)
return {"answer": response.content}
graph_builder = StateGraph(State).add_sequence([analyze_query, retrieve, generate])
graph_builder.add_edge(START, "analyze_query")
graph = graph_builder.compile()
完整代码:
from typing import Literal
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.documents import Document
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langgraph.graph import START, StateGraph
from typing_extensions import Annotated, List, TypedDict
# Load and chunk contents of the blog
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)
# Update metadata (illustration purposes)
total_documents = len(all_splits)
third = total_documents // 3
for i, document in enumerate(all_splits):
if i < third:
document.metadata["section"] = "beginning"
elif i < 2 * third:
document.metadata["section"] = "middle"
else:
document.metadata["section"] = "end"
# Index chunks
vector_store = InMemoryVectorStore(embeddings)
_ = vector_store.add_documents(all_splits)
# Define schema for search
class Search(TypedDict):
"""Search query."""
query: Annotated[str, ..., "Search query to run."]
section: Annotated[
Literal["beginning", "middle", "end"],
...,
"Section to query.",
]
# Define prompt for question-answering
prompt = hub.pull("rlm/rag-prompt")
# Define state for application
class State(TypedDict):
question: str
query: Search
context: List[Document]
answer: str
def analyze_query(state: State):
structured_llm = llm.with_structured_output(Search)
query = structured_llm.invoke(state["question"])
return {"query": query}
def retrieve(state: State):
query = state["query"]
retrieved_docs = vector_store.similarity_search(
query["query"],
filter=lambda doc: doc.metadata.get("section") == query["section"],
)
return {"context": retrieved_docs}
def generate(state: State):
docs_content = "\n\n".join(doc.page_content for doc in state["context"])
messages = prompt.invoke({"question": state["question"], "context": docs_content})
response = llm.invoke(messages)
return {"answer": response.content}
graph_builder = StateGraph(State).add_sequence([analyze_query, retrieve, generate])
graph_builder.add_edge(START, "analyze_query")
graph = graph_builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))

我们可以通过明确要求获取文章末尾的上下文来测试我们的实现。请注意,模型在回答中包含了不同的信息。
for step in graph.stream(
{"question": "What does the end of the post say about Task Decomposition?"},
stream_mode="updates",
):
print(f"{step}\n\n----------------\n")
{'analyze_query': {'query': {'query': 'Task Decomposition', 'section': 'end'}}}
----------------
{'retrieve': {'context': [Document(id='d6cef137-e1e8-4ddc-91dc-b62bd33c6020', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 39221, 'section': 'end'}, page_content='Finite context length: The restricted context capacity limits the inclusion of historical information, detailed instructions, API call context, and responses. The design of the system has to work with this limited communication bandwidth, while mechanisms like self-reflection to learn from past mistakes would benefit a lot from long or infinite context windows. Although vector stores and retrieval can provide access to a larger knowledge pool, their representation power is not as powerful as full attention.\n\n\nChallenges in long-term planning and task decomposition: Planning over a lengthy history and effectively exploring the solution space remain challenging. LLMs struggle to adjust plans when faced with unexpected errors, making them less robust compared to humans who learn from trial and error.'), Document(id='d1834ae1-eb6a-43d7-a023-08dfa5028799', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 39086, 'section': 'end'}, page_content='}\n]\nChallenges#\nAfter going through key ideas and demos of building LLM-centered agents, I start to see a couple common limitations:'), Document(id='ca7f06e4-2c2e-4788-9a81-2418d82213d9', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 32942, 'section': 'end'}, page_content='}\n]\nThen after these clarification, the agent moved into the code writing mode with a different system message.\nSystem message:'), Document(id='1fcc2736-30f4-4ef6-90f2-c64af92118cb', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 35127, 'section': 'end'}, page_content='"content": "You will get instructions for code to write.\\nYou will write a very long answer. Make sure that every detail of the architecture is, in the end, implemented as code.\\nMake sure that every detail of the architecture is, in the end, implemented as code.\\n\\nThink step by step and reason yourself to the right decisions to make sure we get it right.\\nYou will first lay out the names of the core classes, functions, methods that will be necessary, as well as a quick comment on their purpose.\\n\\nThen you will output the content of each file including ALL code.\\nEach file must strictly follow a markdown code block format, where the following tokens must be replaced such that\\nFILENAME is the lowercase file name including the file extension,\\nLANG is the markup code block language for the code\'s language, and CODE is the code:\\n\\nFILENAME\\n\`\`\`LANG\\nCODE\\n\`\`\`\\n\\nYou will start with the \\"entrypoint\\" file, then go to the ones that are imported by that file, and so on.\\nPlease')]}}
----------------
{'generate': {'answer': 'The end of the post highlights that task decomposition faces challenges in long-term planning and adapting to unexpected errors. LLMs struggle with adjusting their plans, making them less robust compared to humans who learn from trial and error. This indicates a limitation in effectively exploring the solution space and handling complex tasks.'}}
----------------
在流式步骤和LangSmith 跟踪中,我们现在可以观察到输入到检索步骤的结构化查询。
查询分析是一个复杂的问题,拥有多种解决方法。请参阅 操操作指南 以获取更多示例。
下一步
我们已经介绍了构建基于数据的基本问答应用的步骤:
- 使用 文档加载器 加载数据
- 使用文本分割器对索引数据进行分块,使其更易于模型使用
- 嵌入数据 并将数据存储在 向量存储
- 在响应传入问题时,检索之前存储的文本块
- 使用检索到的文本块作为上下文生成答案。
在本教程的第二部分中,我们将扩展此处的实现,以支持对话式交互和多步骤检索过程。
延伸阅读: