在用户界面中创建和管理数据集
数据集 使您能够使用一致的数据随时间执行可重复的评估。数据集由 示例 构成,这些示例用于存储输入、输出,以及可选的参考输出。
如需了解有关数据集、评估和示例的更多信息,请阅读评估与数据集概念指南。
本指南概述了在 LangSmith 界面中创建和编辑数据集的各种方法。
创建数据集并添加示例
从追踪项目手动导入
构建数据集的一种常见模式是将应用程序中具有代表性的追踪记录转换为数据集示例。此方法要求您已配置好指向 LangSmith 的追踪功能。
构建数据集的一种强大技术是筛选出最具价值的追踪记录(traces),例如被标记为用户反馈较差的追踪记录,并将其添加到数据集中。 有关如何筛选追踪记录的技巧,请参阅筛选追踪记录指南。
手动将追踪项目中的数据添加到数据集有两种方式。
- 从运行表中多选运行
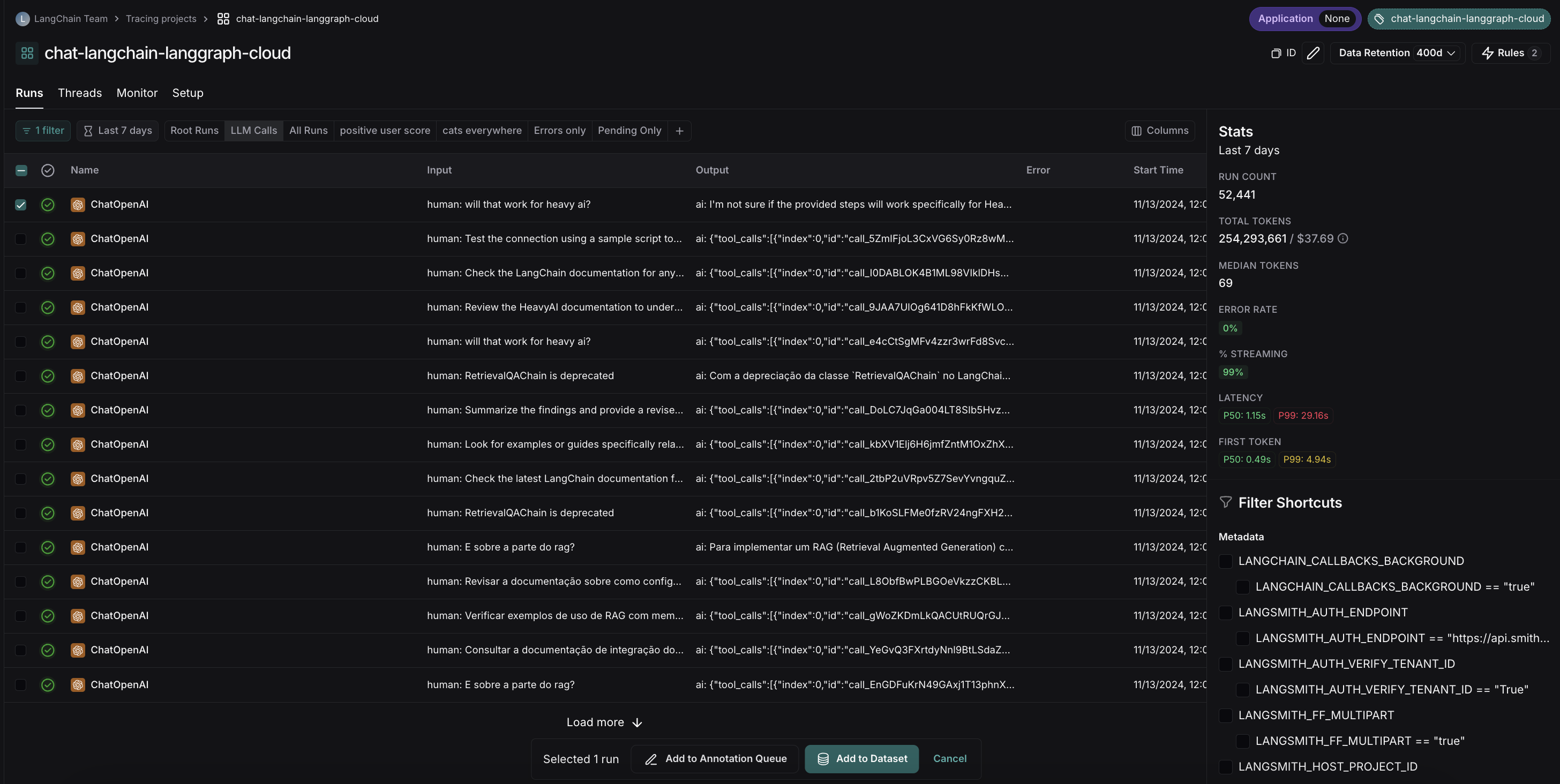
- 导航至运行详情页面,然后单击右上角的
Add to -> Dataset:
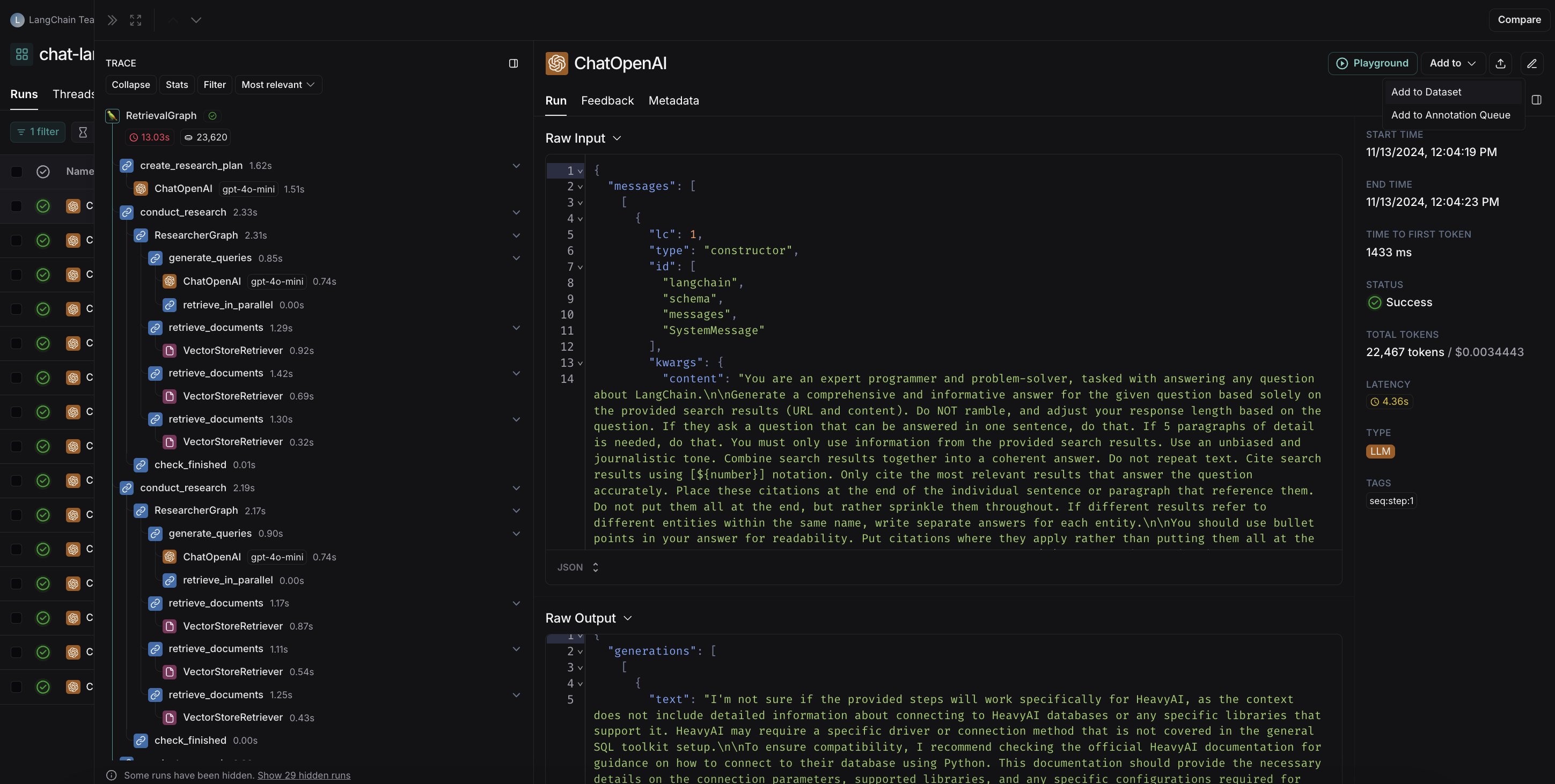
在运行详情页面中选择数据集时,将弹出一个模态框,告知您是否应用了任何转换操作,或架构验证是否失败。例如,下方截图展示了一个正在使用转换操作以优化大语言模型(LLM)运行数据收集的数据集。
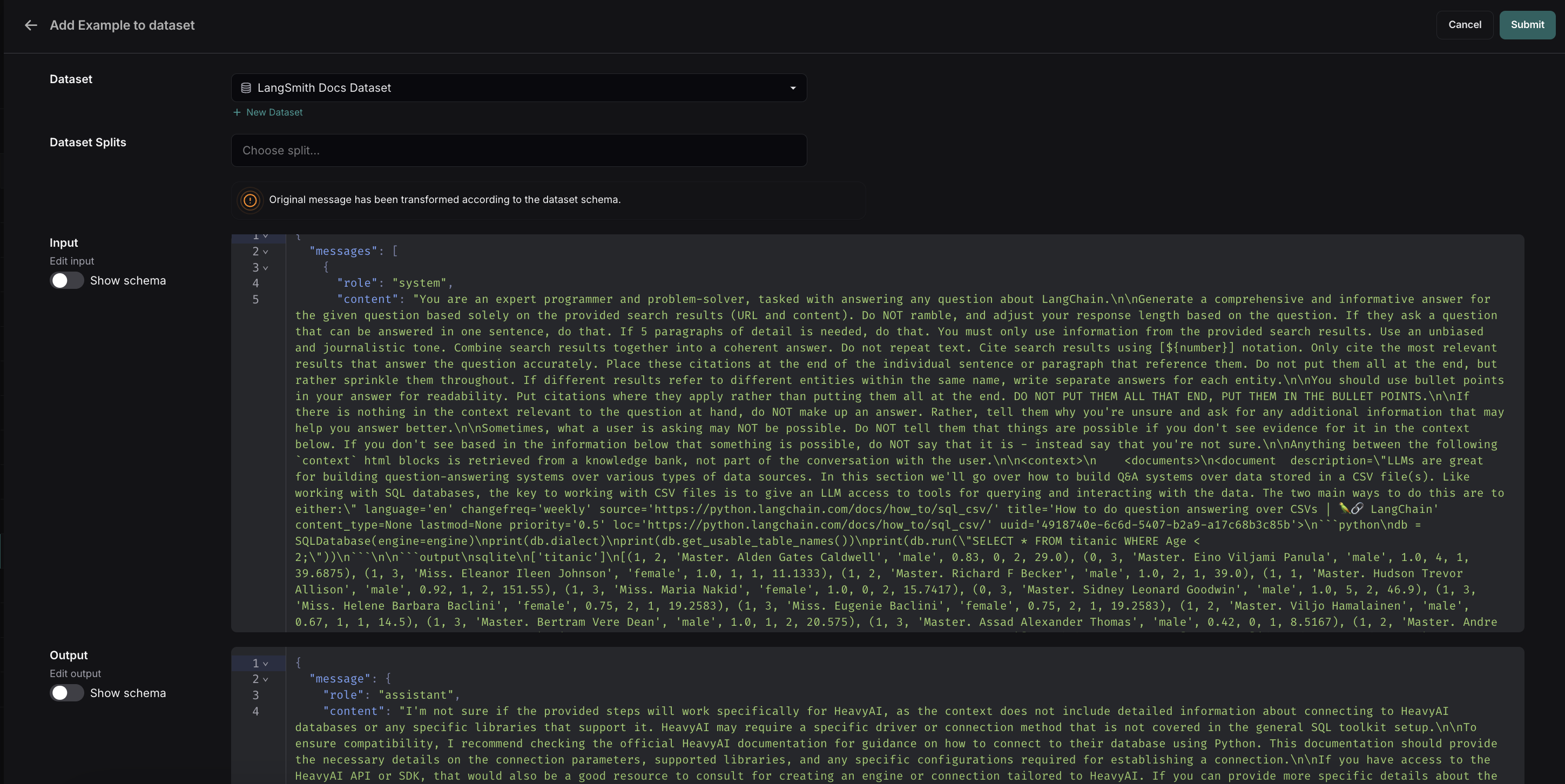
然后,您可以选择在将运行结果添加到数据集之前对其进行编辑。
自动来自追踪项目
您可以使用 运行规则,根据特定条件自动将追踪记录添加到数据集中。例如,您可以添加所有带有特定用例标签的追踪记录,或所有反馈评分较低的追踪记录。
来自标注队列中的示例
如果您依赖领域专家来构建有意义的数据集,请使用 标注队列 为审核人员提供简化的审核视图。人工审核员可在追踪记录加入数据集之前,选择性地修改其输入/输出/参考输出。
标注队列可选择性地配置默认数据集,但您也可以通过屏幕底部的数据集切换器将运行任务添加到任意数据集。选定合适的数据集后,点击 添加到数据集 按钮,或按快捷键 D 将该运行任务添加至该数据集。
您在标注队列中对运行所做的任何修改都将同步至数据集,且与该运行关联的所有元数据也将一并复制。
请注意,您还可以通过自动化规则设置规则,将符合特定条件的运行添加到标注队列中。
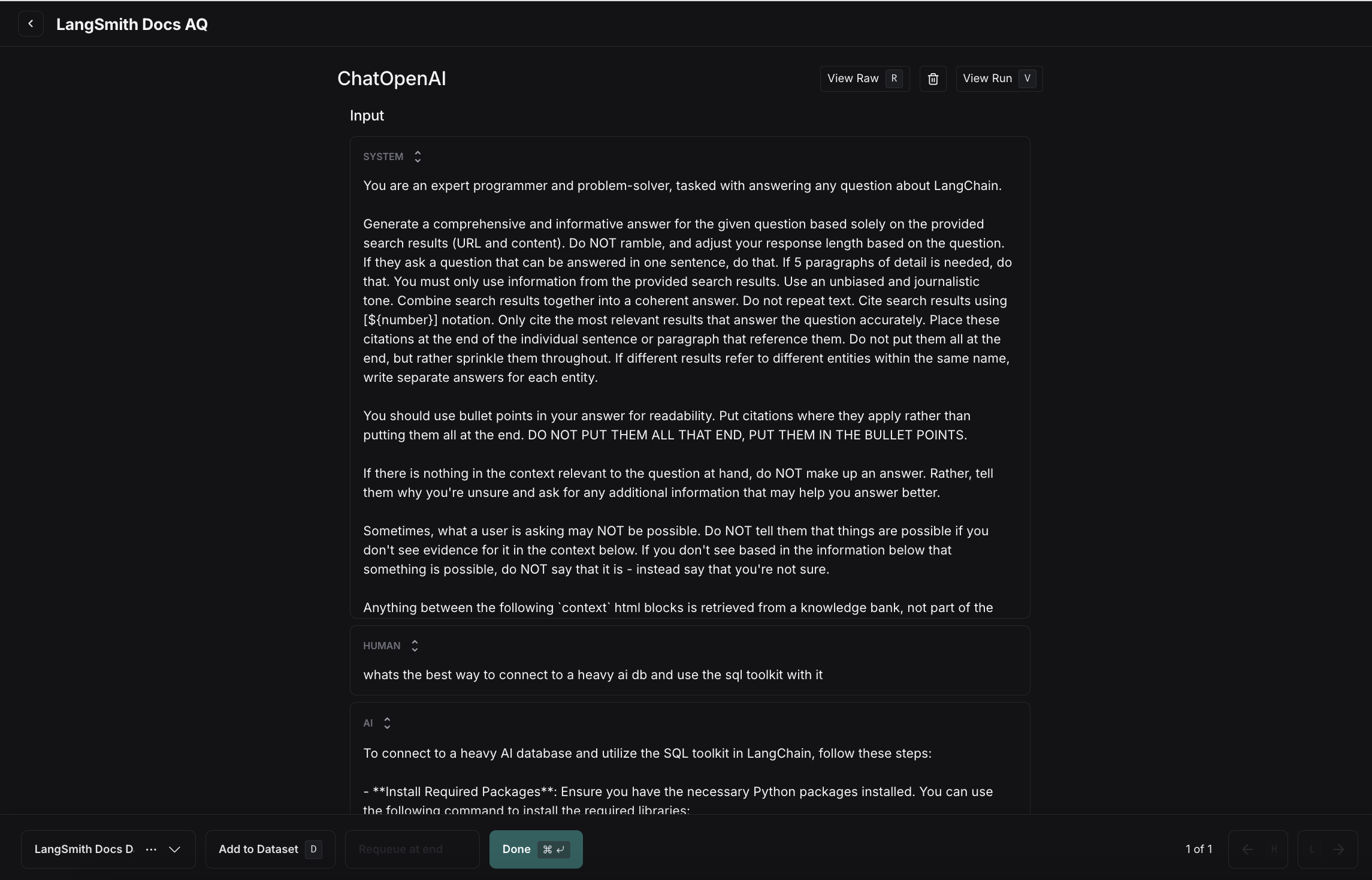
来自提示词游乐场
在提示词游乐场页面中,选择设置评估,如果要创建新数据集,请单击+新建;或者从现有数据集中进行选择。
在 Playground 中不支持为包含嵌套键的数据集内联创建数据集。若要添加或编辑包含嵌套键的示例,您必须从数据集页面进行编辑。
编辑示例:
- 使用 +行 向数据集添加新示例
- 使用表格右侧的 ⋮ 下拉菜单删除示例
- 如果您正在创建一个无需参考答案的数据集,请使用列标题中的×按钮移除“参考输出”列。注意:此操作不可撤销。
从CSV或JSONL文件导入数据集
在数据集与实验页面上,点击+新建数据集,然后从CSV或JSONL文件导入现有数据集。
从数据集页面创建新数据集
在数据集与实验页面上,点击+新建数据集,然后选择创建空数据集。您可选择性地创建一个数据集模式来验证您的数据集。
然后,要内联添加示例,请转到示例选项卡,然后点击+ 示例。这将允许您以内联 JSON 格式定义示例。
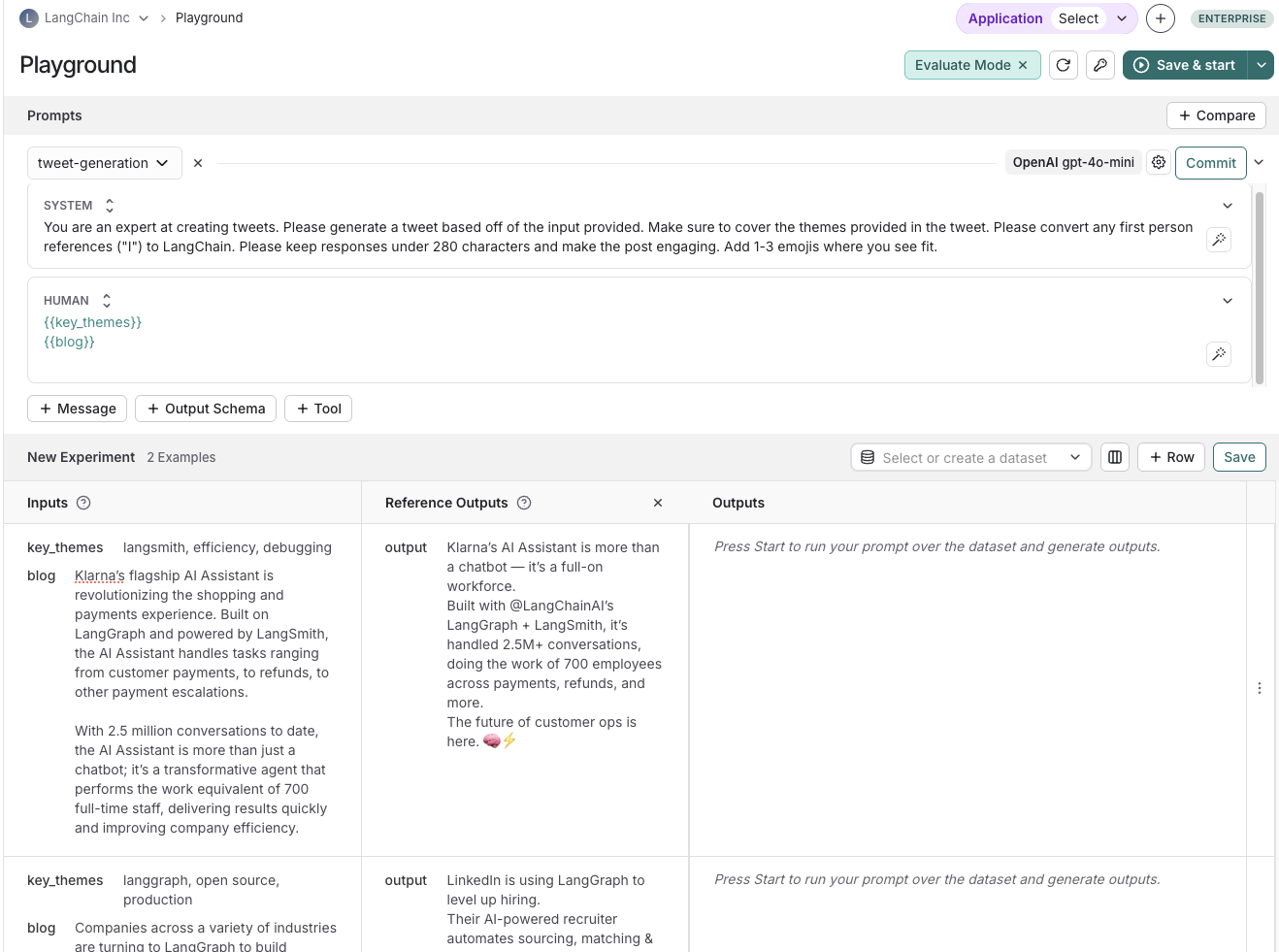
通过数据集UI添加由大语言模型生成的合成示例
如果您的数据集已定义了模式,当您点击 + Example 时,将看到一个 Generate examples 的选项。此操作将利用大语言模型(LLM)生成合成示例。
你需要执行以下操作:
- 选择少量示例:选择一组示例来指导大语言模型(LLM)的生成。您可以从数据集中手动选择这些示例,也可以使用自动选择选项。
- 指定示例数量:输入您要生成的合成示例数量。
- 配置 API 密钥:请确保已在“API 密钥”链接处输入您的 OpenAI API 密钥。
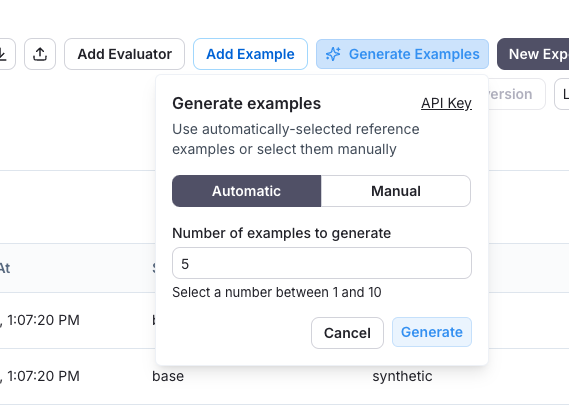
点击“生成”后,示例将显示在页面上。您可以选择要添加到数据集中的示例,并可在最终确定前对其进行编辑。
每个示例都将根据您指定的数据集模式进行验证,并在源元数据中标记为“合成”。

管理数据集
创建数据集模式
LangSmith 数据集用于存储任意 JSON 对象。我们建议(但不强制要求)为数据集定义一个模式(schema),以确保其符合特定的 JSON 模式。数据集模式采用标准的 JSON Schema 进行定义,并额外支持若干 预置类型,以便更便捷地为消息(messages)、工具(tools)等常见基本类型进行标注。
您模式中的某些字段具有 + Transformations 选项。
转换是预处理步骤;如果启用,当您将示例添加到数据集时,这些步骤会更新您的示例。
例如,convert to OpenAI messages 转换会将类似消息的对象(如 LangChain 消息)转换为 OpenAI 消息格式。
有关所有可用转换的完整列表,请参阅我们的参考文档。
如果您计划从 LangChain 的 聊天模型(ChatModels) 或使用 LangSmith OpenAI 封装器 调用 OpenAI 接口来收集生产环境中的追踪数据(traces),我们提供了一个预构建的聊天模型(Chat Model)数据模式,可将消息和工具转换为符合行业标准的 OpenAI 格式,以便在下游测试中与任意模型配合使用。您还可以自定义模板设置,以满足您的具体使用场景。
请参阅数据集转换参考以了解更多信息。
创建和管理数据集划分
数据集划分(Dataset splits)是指对数据集进行的分割,可用于对数据进行分段处理。例如,在机器学习工作流中,通常会将数据集划分为训练集、验证集和测试集。这种划分有助于防止过拟合——即模型在训练数据上表现良好,但在未见过的数据上表现较差。在评估工作流中,当您的数据集包含多个类别、而您希望对这些类别分别进行评估时,或当您正在测试一种未来可能纳入数据集的新应用场景、但目前希望将其单独保留时,这种划分方式同样很有用。请注意,通过元数据(metadata)也可手动实现类似效果;但我们预期“划分”主要用于数据集更高层级的组织,即将数据集拆分为若干独立组以供评估之用;而元数据则更多用于存储样本的相关信息,例如标签及样本来源等。
在机器学习中,最佳实践是将数据集划分彼此分离(每个样本仅属于一个划分)。 然而,在 LangSmith 中,我们允许您为同一样本选择多个划分,因为这在某些评估工作流中是合理的——例如,当某个样本属于多个类别,而您希望针对这些类别分别评估您的应用时。
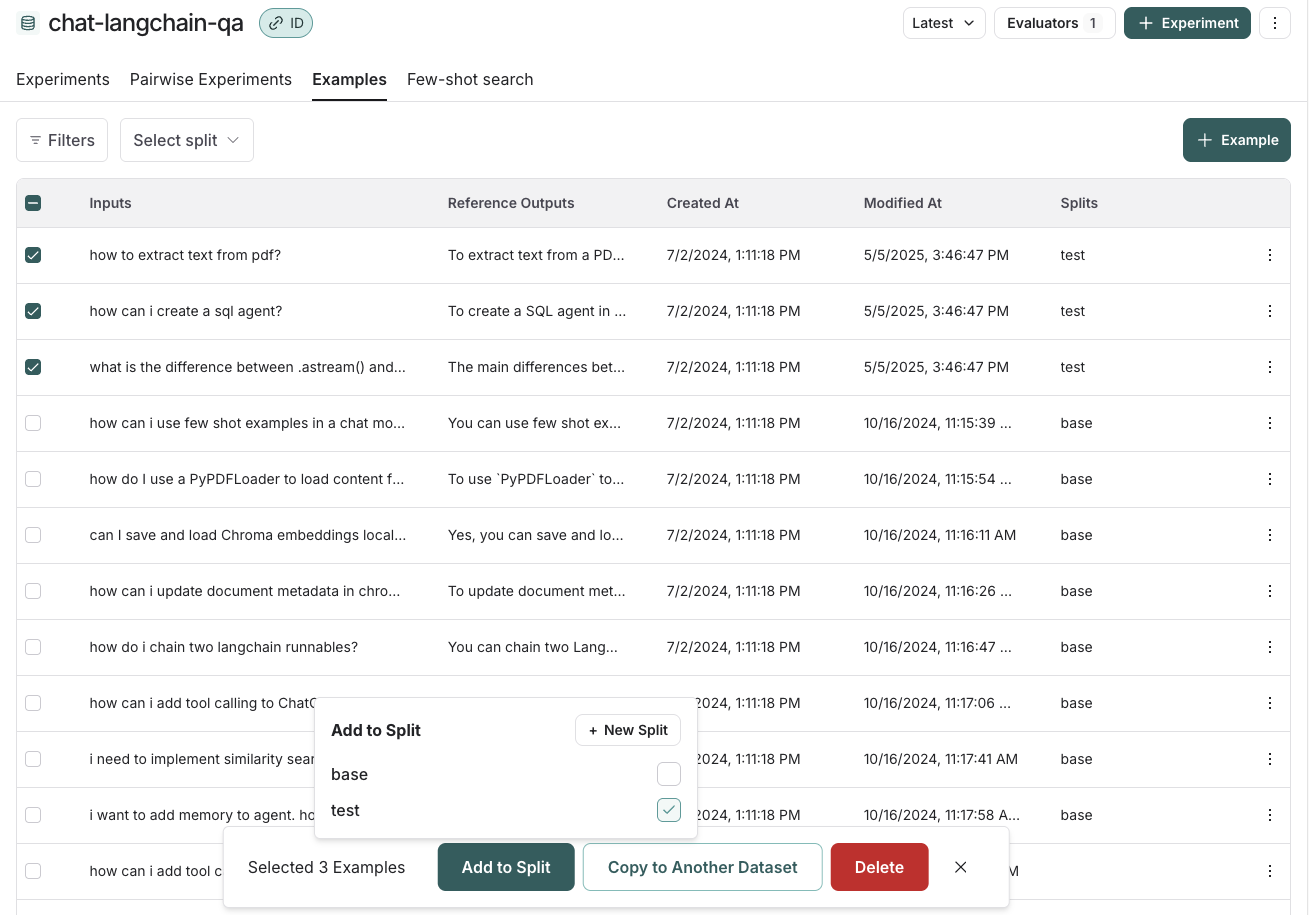
为了在应用中创建和管理数据集划分(Split),您可以先在数据集中选择若干样本,然后点击“添加到划分”。在随后弹出的菜单中, 您可以为所选样本勾选或取消勾选相应的划分,也可以创建一个新的划分。
编辑示例元数据
您可以通过点击某个示例,然后在弹出窗口右上方点击“编辑”来为示例添加元数据。
在此页面中,您可以更新或删除现有元数据,也可以添加新的元数据。您可以利用此功能存储有关示例的信息(例如标签或版本信息),以便在分析实验结果时按这些元数据进行分组,或在SDK中调用list_examples时按这些元数据进行筛选。
筛选示例
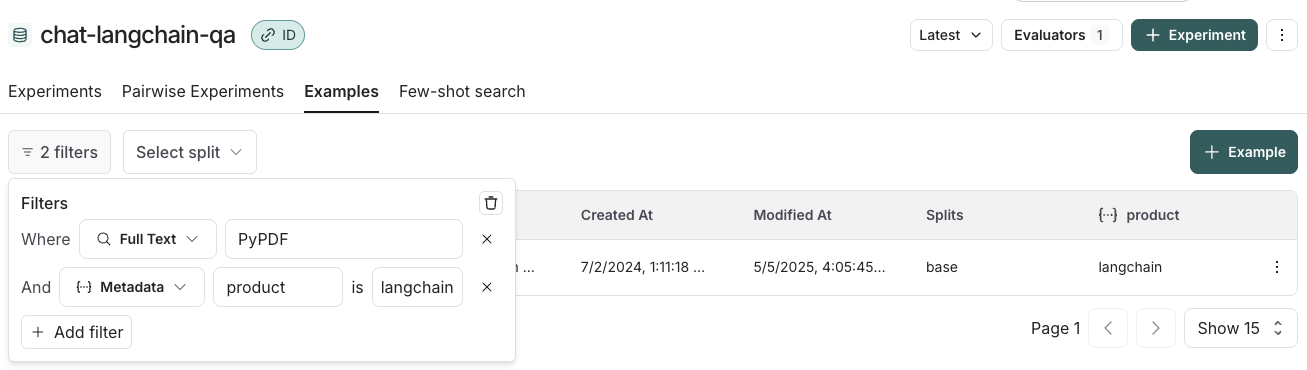
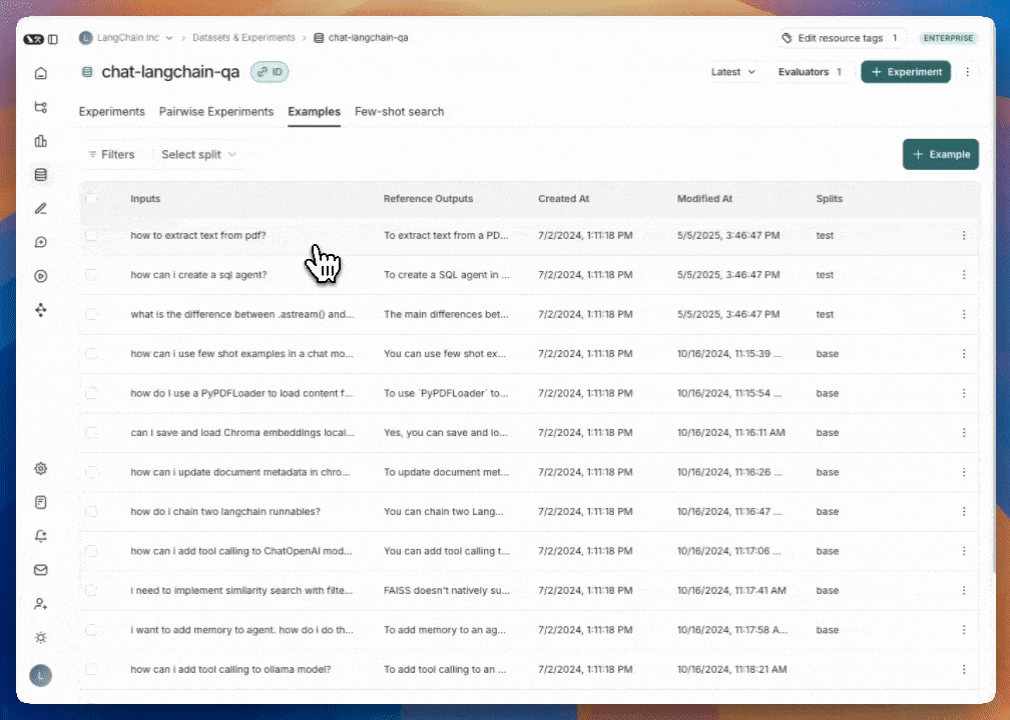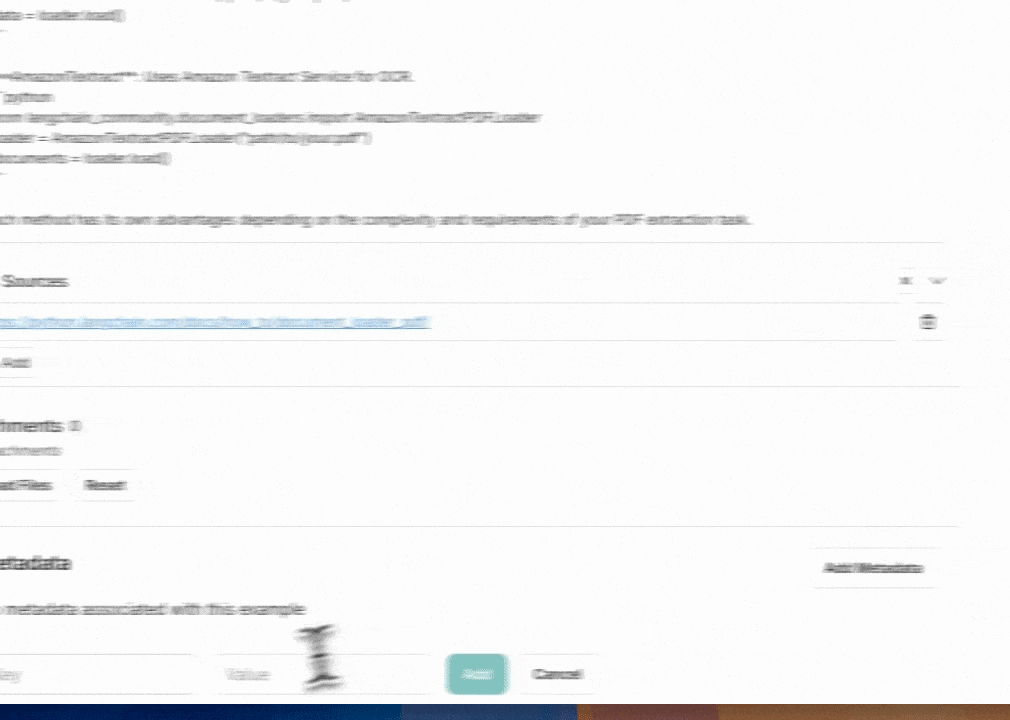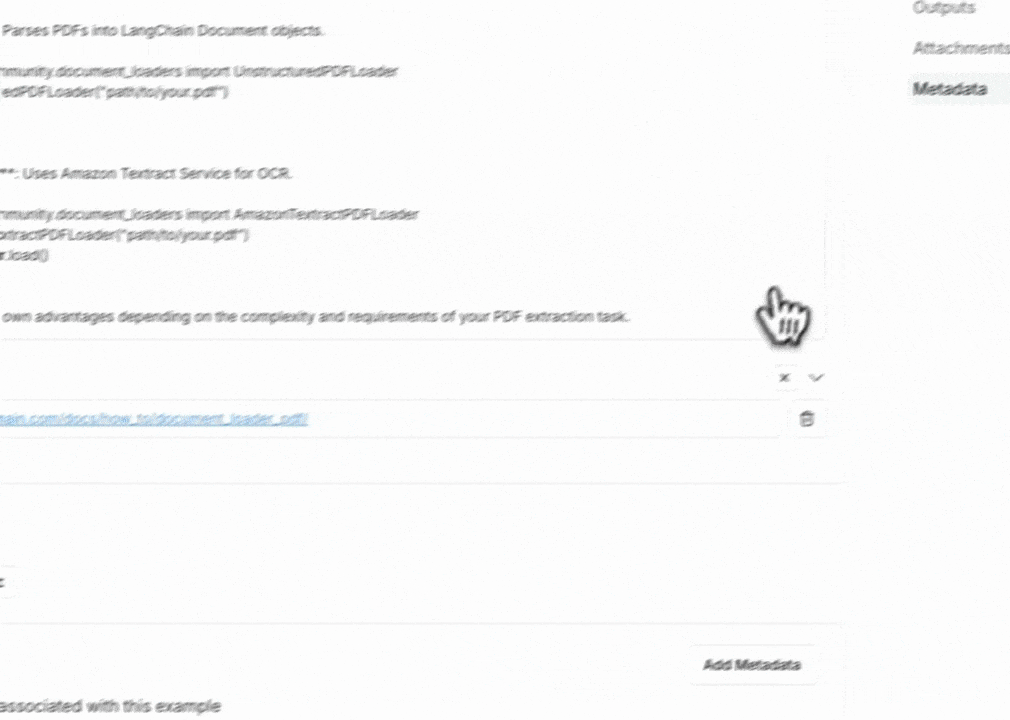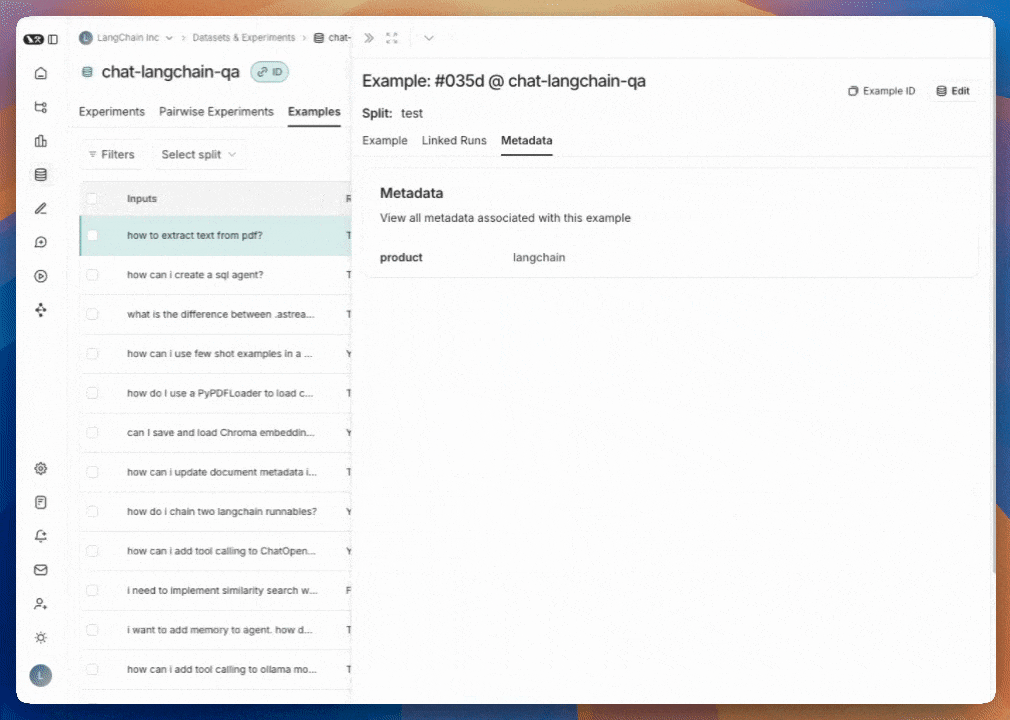
您可以按数据集划分(split)、元数据键/值对或对示例进行全文搜索来筛选示例。这些筛选选项位于示例表格的左上方。
- 按数据集划分筛选:选择划分 > 选择一个划分以进行筛选
- 按元数据筛选:筛选器 > 从下拉菜单中选择“元数据” > 选择要用于筛选的元数据键和值
- 全文搜索:筛选条件 > 从下拉菜单中选择“全文” > 输入您的搜索条件
您可以添加多个筛选条件,表格中仅显示满足所有筛选条件的示例。