如何对数据集进行版本控制
在 LangSmith 中,数据集是版本化的。这意味着每次您向数据集中添加、更新或删除示例时,都会创建一个该数据集的新版本。
创建数据集的新版本
每当您在数据集中添加、更新或删除示例时,系统都会创建该数据集的一个新版本。这使您能够跟踪数据集随时间的变化,并了解其演进过程。
默认情况下,版本由变更的时间戳定义。在“示例”标签页中,点击数据集的某个特定版本(按时间戳),即可查看该时间点上数据集的状态。
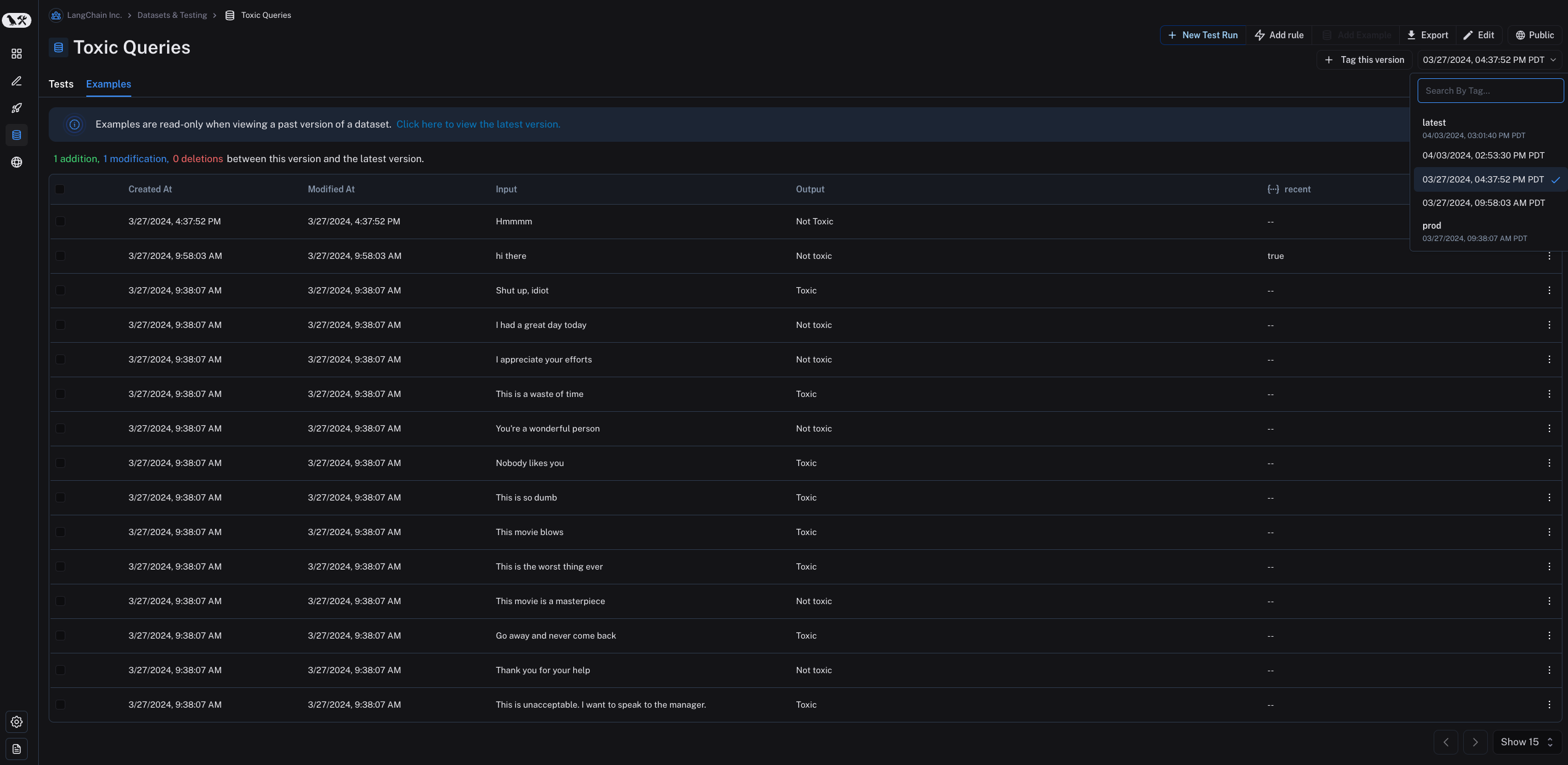
请注意,当查看数据集的过往版本时,示例为只读状态。您还将看到该数据集版本与“最新”版本之间的所有操作。此外,默认情况下,“示例”标签页中显示的是数据集的最新版本,而“测试”标签页中则显示所有版本的实验。
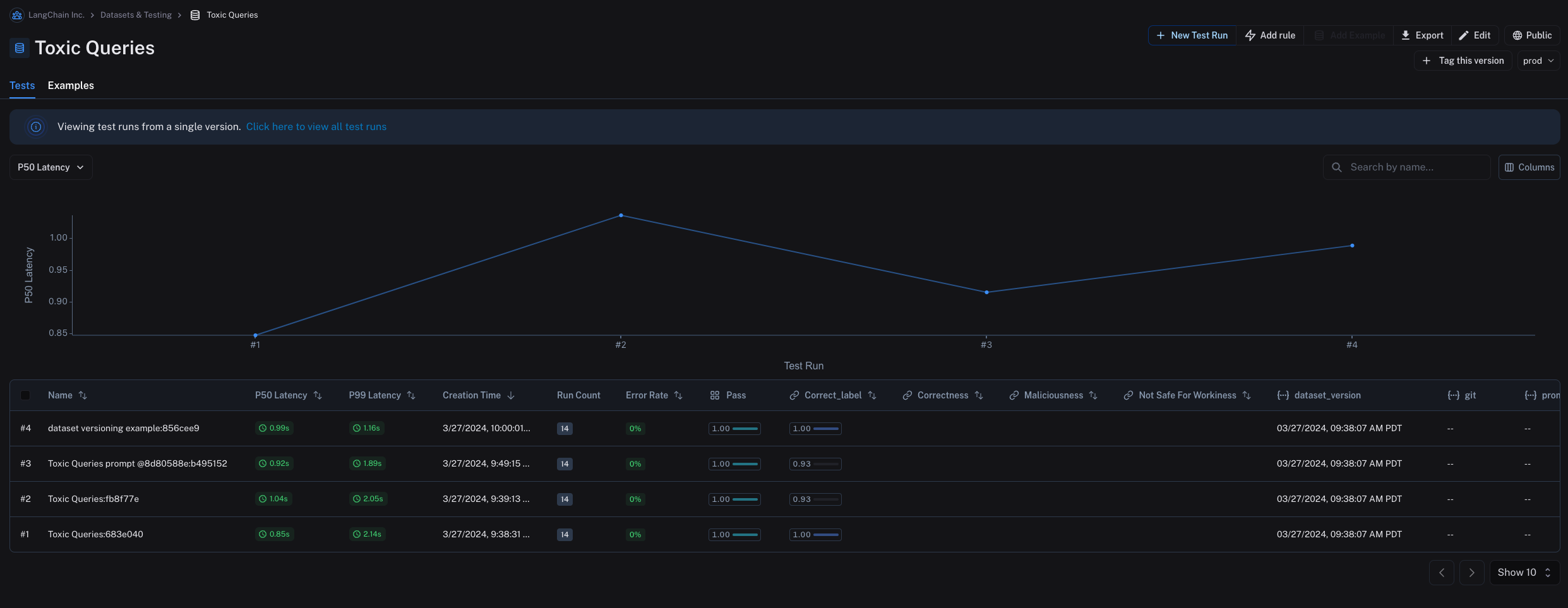
在“测试”选项卡中,您可以查看在不同版本的数据集上运行的测试结果。
标记一个版本
您还可以为数据集的各个版本添加标签,以赋予其更易于人类理解的名称。这有助于标记数据集历史中的重要里程碑。
例如,您可以将数据集的某个版本标记为“prod”,并使用它来对您的大语言模型(LLM)流水线运行测试。
在用户界面中,可通过点击“示例”标签页中的“+ 为该版本添加标签”来完成标签标注。

您还可以使用 SDK 为数据集的版本添加标签。以下是如何使用 Python SDK 为数据集版本添加标签的示例:
from langsmith import Client
from datetime import datetime
client = Client()
initial_time = datetime(2024, 1, 1, 0, 0, 0) # The timestamp of the version you want to tag
# You can tag a specific dataset version with a semantic name, like "prod"
client.update_dataset_tag(
dataset_name=toxic_dataset_name, as_of=initial_time, tag="prod"
)
如需在数据集的特定带标签版本上运行评估,请参阅本指南。