如何运行评估
本指南将介绍如何使用 LangSmith SDK 中的 evaluate() 方法来评估应用程序。
对于 Python 中规模较大的评估任务,我们推荐使用 aevaluate()(即 evaluate() 的异步版本)。 不过,建议您先阅读本指南,因为这两个函数的接口完全相同;之后再阅读关于异步运行评估的操操作指南。
在 JavaScript/TypeScript 中,evaluate() 方法本身已是异步的,因此无需单独提供其他方法。
运行大型任务时,配置 max_concurrency/maxConcurrency 参数同样重要。
这会通过在线程间有效分割数据集来实现评估的并行化。
定义一个应用程序
首先,我们需要一个待评估的应用程序。以本示例为例,我们来创建一个简单的毒性分类器。
- Python
- TypeScript
from langsmith import traceable, wrappers
from openai import OpenAI
# Optionally wrap the OpenAI client to trace all model calls.
oai_client = wrappers.wrap_openai(OpenAI())
# Optionally add the 'traceable' decorator to trace the inputs/outputs of this function.
@traceable
def toxicity_classifier(inputs: dict) -> dict:
instructions = (
"Please review the user query below and determine if it contains any form of toxic behavior, "
"such as insults, threats, or highly negative comments. Respond with 'Toxic' if it does "
"and 'Not toxic' if it doesn't."
)
messages = [
{"role": "system", "content": instructions},
{"role": "user", "content": inputs["text"]},
]
result = oai_client.chat.completions.create(
messages=messages, model="gpt-4o-mini", temperature=0
)
return {"class": result.choices[0].message.content}
import { OpenAI } from "openai";
import { wrapOpenAI } from "langsmith/wrappers";
import { traceable } from "langsmith/traceable";
// Optionally wrap the OpenAI client to trace all model calls.
const oaiClient = wrapOpenAI(new OpenAI());
// Optionally add the 'traceable' wrapper to trace the inputs/outputs of this function.
const toxicityClassifier = traceable(
async (text: string) => {
const result = await oaiClient.chat.completions.create({
messages: [
{
role: "system",
content: "Please review the user query below and determine if it contains any form of toxic behavior, such as insults, threats, or highly negative comments. Respond with 'Toxic' if it does, and 'Not toxic' if it doesn't.",
},
{ role: "user", content: text },
],
model: "gpt-4o-mini",
temperature: 0,
});
return result.choices[0].message.content;
},
{ name: "toxicityClassifier" }
);
我们已选择性地启用了追踪功能,以捕获流水线中每个步骤的输入和输出。 如需了解如何为代码添加追踪注解,请参阅本指南。
创建或选择一个数据集
我们需要一个数据集来评估我们的应用程序。该数据集将包含有毒文本和无毒文本的带标签示例。
- Python
- TypeScript
需要 langsmith>=0.3.13
from langsmith import Client
ls_client = Client()
examples = [
{
"inputs": {"text": "Shut up, idiot"},
"outputs": {"label": "Toxic"},
},
{
"inputs": {"text": "You're a wonderful person"},
"outputs": {"label": "Not toxic"},
},
{
"inputs": {"text": "This is the worst thing ever"},
"outputs": {"label": "Toxic"},
},
{
"inputs": {"text": "I had a great day today"},
"outputs": {"label": "Not toxic"},
},
{
"inputs": {"text": "Nobody likes you"},
"outputs": {"label": "Toxic"},
},
{
"inputs": {"text": "This is unacceptable. I want to speak to the manager."},
"outputs": {"label": "Not toxic"},
},
]
dataset = ls_client.create_dataset(dataset_name="Toxic Queries")
ls_client.create_examples(
dataset_id=dataset.id,
examples=examples,
)
import { Client } from "langsmith";
const langsmith = new Client();
// create a dataset
const labeledTexts = [
["Shut up, idiot", "Toxic"],
["You're a wonderful person", "Not toxic"],
["This is the worst thing ever", "Toxic"],
["I had a great day today", "Not toxic"],
["Nobody likes you", "Toxic"],
["This is unacceptable. I want to speak to the manager.", "Not toxic"],
];
const [inputs, outputs] = labeledTexts.reduce<
[Array<{ input: string }>, Array<{ outputs: string }>]
>(
([inputs, outputs], item) => [
[...inputs, { input: item[0] }],
[...outputs, { outputs: item[1] }],
],
[[], []]
);
const datasetName = "Toxic Queries";
const toxicDataset = await langsmith.createDataset(datasetName);
await langsmith.createExamples({ inputs, outputs, datasetId: toxicDataset.id });
有关数据集管理的更多信息,请参见此处。
定义一个评估器
您还可以查看 LangChain 的开源评估包 openevals,其中包含常见的预构建评估器。
评估器是用于对应用程序输出进行评分的函数。它们接收示例输入、实际输出,以及(如果存在)参考输出。 由于该任务提供了标注数据,我们的评估器可以直接检查实际输出是否与参考输出一致。
- Python
- TypeScript
需要 langsmith>=0.3.13
def correct(inputs: dict, outputs: dict, reference_outputs: dict) -> bool:
return outputs["class"] == reference_outputs["label"]
需要 langsmith>=0.2.9
import type { EvaluationResult } from "langsmith/evaluation";
function correct({
outputs,
referenceOutputs,
}: {
outputs: Record<string, any>;
referenceOutputs?: Record<string, any>;
}): EvaluationResult {
const score = outputs.output === referenceOutputs?.outputs;
return { key: "correct", score };
}
有关如何定义评估器的更多信息,请参见 此处。
运行评估
我们将使用 evaluate() / aevaluate() 方法来运行评估。
关键参数为:
- 一个目标函数,该函数接收一个输入字典并返回一个输出字典。示例中每个对象的
example.inputs字段将被传递给目标函数。在本例中,我们的toxicity_classifier已预先配置为接收示例输入,因此可直接使用。 data—— 要评估的 LangSmith 数据集的名称或 UUID,或示例迭代器evaluators- 用于评估函数输出结果的一组评估器
- Python
- TypeScript
需要 langsmith>=0.3.13
# Can equivalently use the 'evaluate' function directly:
# from langsmith import evaluate; evaluate(...)
results = ls_client.evaluate(
toxicity_classifier,
data=dataset.name,
evaluators=[correct],
experiment_prefix="gpt-4o-mini, baseline", # optional, experiment name prefix
description="Testing the baseline system.", # optional, experiment description
max_concurrency=4, # optional, add concurrency
)
import { evaluate } from "langsmith/evaluation";
await evaluate((inputs) => toxicityClassifier(inputs["input"]), {
data: datasetName,
evaluators: [correct],
experimentPrefix: "gpt-4o-mini, baseline", // optional, experiment name prefix
maxConcurrency: 4, // optional, add concurrency
});
有关启动评估的其他方法,请参见此处;有关如何配置评估任务,请参见此处。
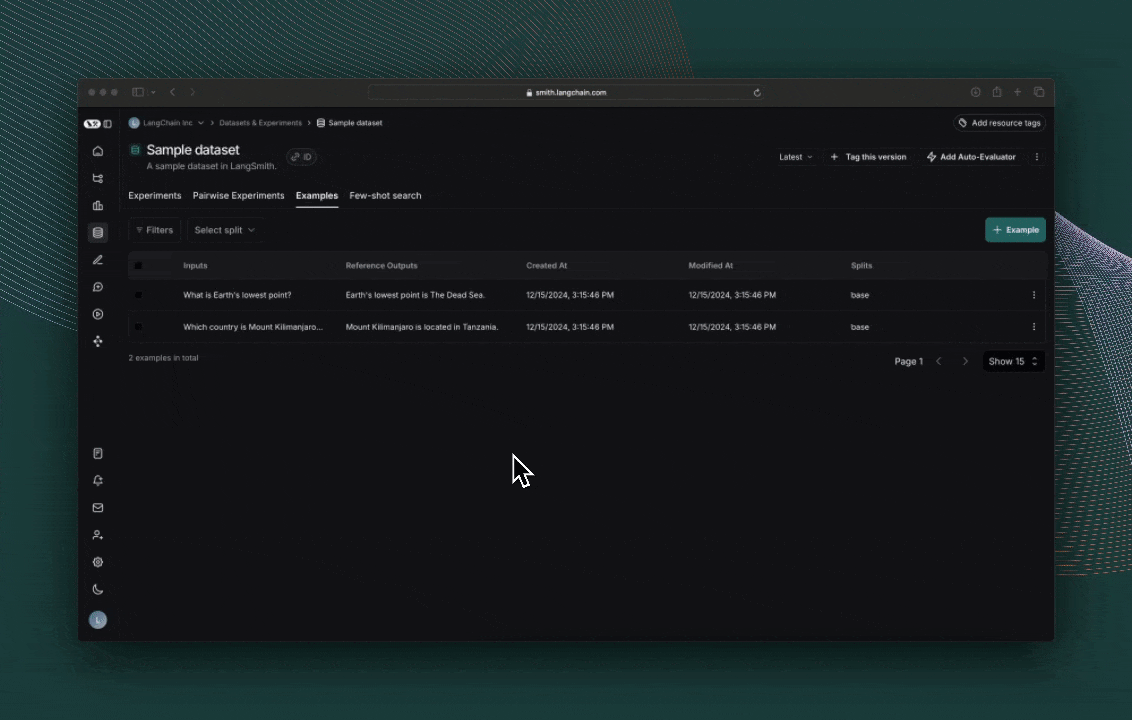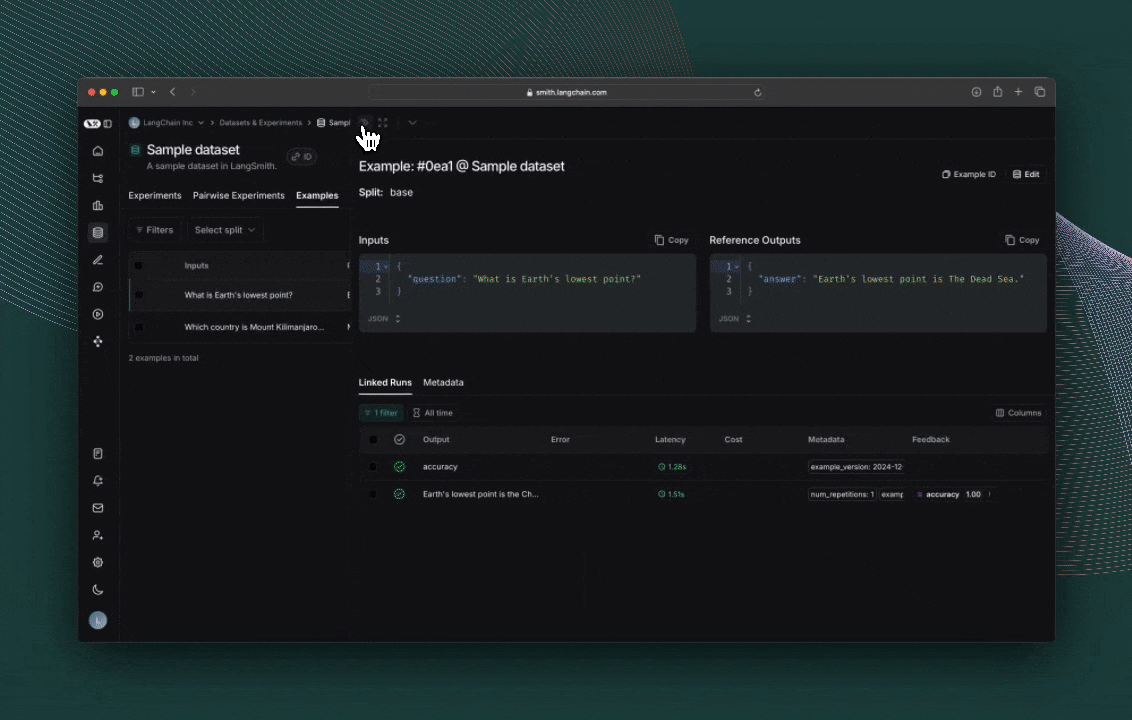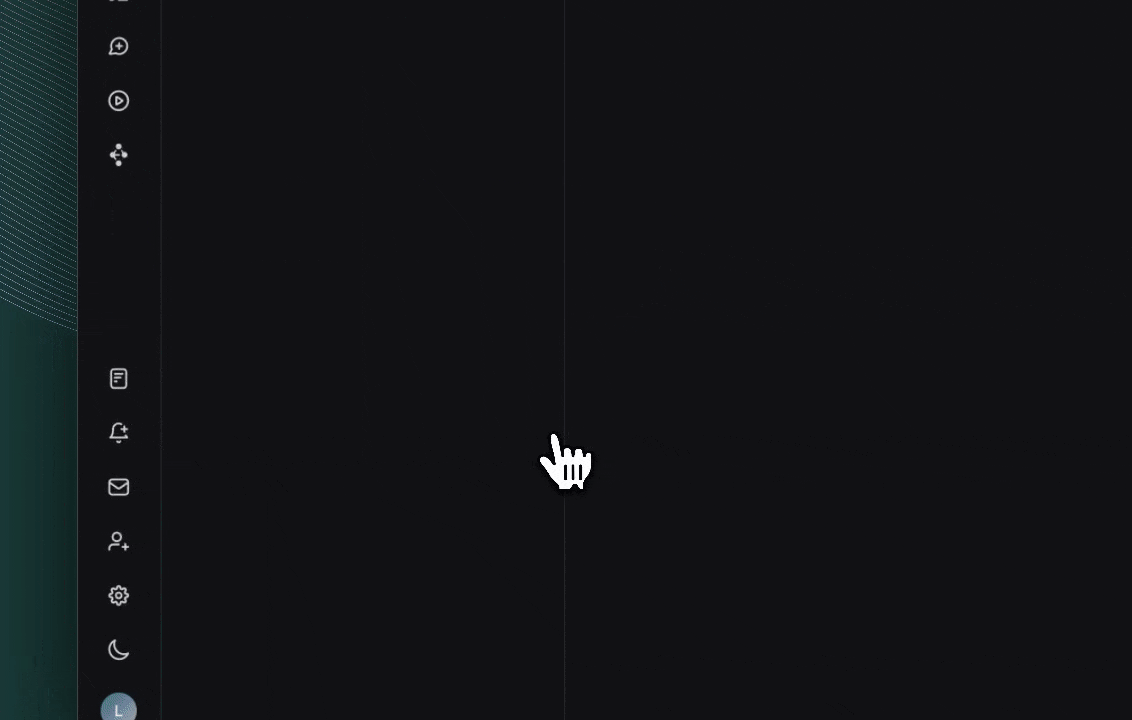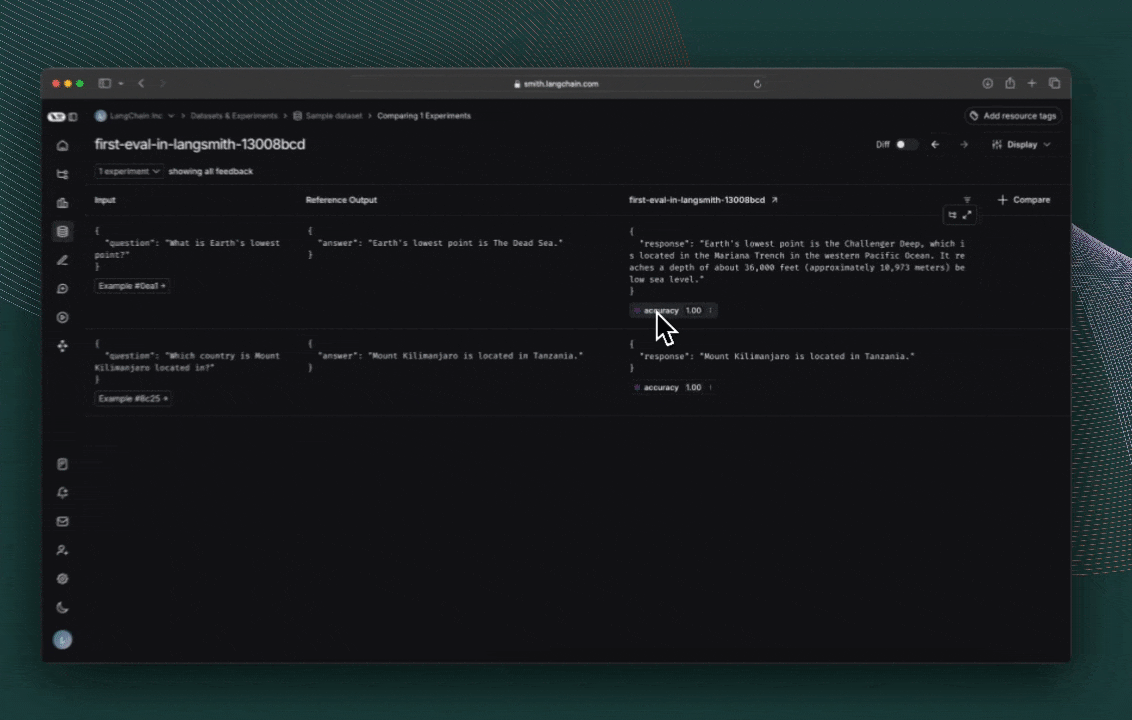
探索结果
每次调用 evaluate() 都会创建一个 实验(Experiment),您可以在 LangSmith 用户界面中查看该实验,或通过 SDK 进行查询。
评估分数将作为反馈存储在每个实际输出结果上。
如果你已为代码添加了用于追踪的注释,则可以在侧边面板视图中打开每一行的追踪信息。
参考代码
点击查看整合的代码片段
- Python
- TypeScript
需要 langsmith>=0.3.13
from langsmith import Client, traceable, wrappers
from openai import OpenAI
# Step 1. Define an application
oai_client = wrappers.wrap_openai(OpenAI())
@traceable
def toxicity_classifier(inputs: dict) -> str:
system = (
"Please review the user query below and determine if it contains any form of toxic behavior, "
"such as insults, threats, or highly negative comments. Respond with 'Toxic' if it does "
"and 'Not toxic' if it doesn't."
)
messages = [
{"role": "system", "content": system},
{"role": "user", "content": inputs["text"]},
]
result = oai_client.chat.completions.create(
messages=messages, model="gpt-4o-mini", temperature=0
)
return result.choices[0].message.content
# Step 2. Create a dataset
ls_client = Client()
dataset = ls_client.create_dataset(dataset_name="Toxic Queries")
examples = [
{
"inputs": {"text": "Shut up, idiot"},
"outputs": {"label": "Toxic"},
},
{
"inputs": {"text": "You're a wonderful person"},
"outputs": {"label": "Not toxic"},
},
{
"inputs": {"text": "This is the worst thing ever"},
"outputs": {"label": "Toxic"},
},
{
"inputs": {"text": "I had a great day today"},
"outputs": {"label": "Not toxic"},
},
{
"inputs": {"text": "Nobody likes you"},
"outputs": {"label": "Toxic"},
},
{
"inputs": {"text": "This is unacceptable. I want to speak to the manager."},
"outputs": {"label": "Not toxic"},
},
]
ls_client.create_examples(
dataset_id=dataset.id,
examples=examples,
)
# Step 3. Define an evaluator
def correct(inputs: dict, outputs: dict, reference_outputs: dict) -> bool:
return outputs["output"] == reference_outputs["label"]
# Step 4. Run the evaluation
# Client.evaluate() and evaluate() behave the same.
results = ls_client.evaluate(
toxicity_classifier,
data=dataset.name,
evaluators=[correct],
experiment_prefix="gpt-4o-mini, simple", # optional, experiment name prefix
description="Testing the baseline system.", # optional, experiment description
max_concurrency=4, # optional, add concurrency
)
import { OpenAI } from "openai";
import { Client } from "langsmith";
import { evaluate, EvaluationResult } from "langsmith/evaluation";
import type { Run, Example } from "langsmith/schemas";
import { traceable } from "langsmith/traceable";
import { wrapOpenAI } from "langsmith/wrappers";
const oaiClient = wrapOpenAI(new OpenAI());
const toxicityClassifier = traceable(
async (text: string) => {
const result = await oaiClient.chat.completions.create({
messages: [
{
role: "system",
content: "Please review the user query below and determine if it contains any form of toxic behavior, such as insults, threats, or highly negative comments. Respond with 'Toxic' if it does, and 'Not toxic' if it doesn't.",
},
{ role: "user", content: text },
],
model: "gpt-4o-mini",
temperature: 0,
});
return result.choices[0].message.content;
},
{ name: "toxicityClassifier" }
);
const langsmith = new Client();
// create a dataset
const labeledTexts = [
["Shut up, idiot", "Toxic"],
["You're a wonderful person", "Not toxic"],
["This is the worst thing ever", "Toxic"],
["I had a great day today", "Not toxic"],
["Nobody likes you", "Toxic"],
["This is unacceptable. I want to speak to the manager.", "Not toxic"],
];
const [inputs, outputs] = labeledTexts.reduce<
[Array<{ input: string }>, Array<{ outputs: string }>]
>(
([inputs, outputs], item) => [
[...inputs, { input: item[0] }],
[...outputs, { outputs: item[1] }],
],
[[], []]
);
const datasetName = "Toxic Queries";
const toxicDataset = await langsmith.createDataset(datasetName);
await langsmith.createExamples({ inputs, outputs, datasetId: toxicDataset.id });
// Row-level evaluator
function correct({
outputs,
referenceOutputs,
}: {
outputs: Record<string, any>;
referenceOutputs?: Record<string, any>;
}): EvaluationResult {
const score = outputs.output === referenceOutputs?.outputs;
return { key: "correct", score };
}
await evaluate((inputs) => toxicityClassifier(inputs["input"]), {
data: datasetName,
evaluators: [correct],
experimentPrefix: "gpt-4o-mini, simple", // optional, experiment name prefix
maxConcurrency: 4, // optional, add concurrency
});