计算基于令牌的追踪成本
在深入阅读本内容之前,可能需要先阅读以下内容:
LangSmith 允许您根据大语言模型调用所使用的 Token 数量来追踪追踪链(trace)的成本。 这些成本会汇总至追踪链级别和项目级别。
为使LangSmith能够准确计算基于Token的费用,您需要在追踪记录中提供每次大语言模型(LLM)调用的Token数量,并在运行元数据中同时上传ls_provider和ls_model_name。
- 如果您正在使用 LangSmith 的 Python 或 TypeScript/JavaScript SDK,请务必仔细阅读本指南。
- 如果您正在使用 LangChain 的 Python 或 TypeScript/JavaScript 版本,
ls_provider和ls_model_name以及对应的 token 数量将自动发送至 LangSmith。
如果 ls_model_name 在 extra.metadata 中不存在,则可能从 extra.invocation_metadata 中使用其他字段来估算 token 数量并计算费用。以下字段将按优先级顺序使用:
metadata.ls_model_nameinvocation_params.modelinvocation_params.model_nameinvocation_params.model_id(仅用于成本计算)invocation_params.model_path(仅用于成本计算)invocation_params.endpoint_name(仅用于成本计算)
一旦您已向LangSmith正确发送了相关信息,就必须在LangSmith设置中配置模型定价映射。 为此,请导航至模型定价映射页面。 在此处,您可以为每种模型与提供商的组合设置每个Token的成本。该信息限定于工作区范围内。
模型定价映射表中已预置了多个 OpenAI 模型的默认条目,您可以根据需要克隆并修改这些条目。
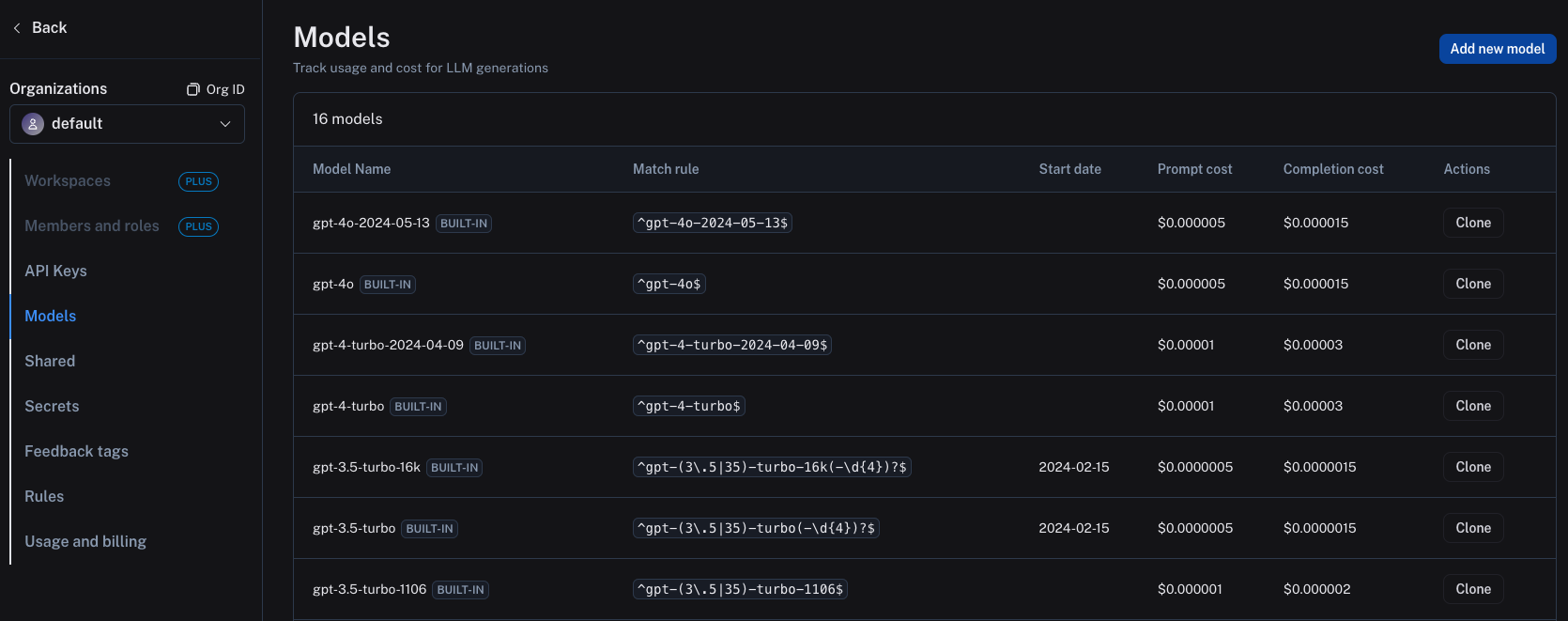
要在模型定价映射中创建一个新条目,请单击右上角的Add new model按钮。
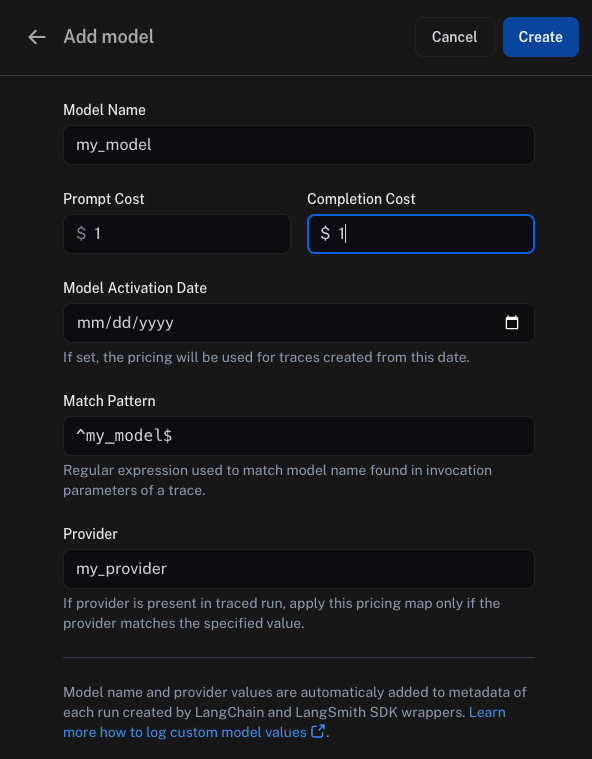
此处,您可以指定以下字段:
Model Name: 模型名称,也将用于为模型定价映射中的条目命名。Prompt Cost: 模型每个输入词元的成本。该数值乘以提示词中的词元数量,即可计算出提示词成本。Completion Cost: 模型每个输出词元的成本。该数值乘以补全内容中的词元数量,即可计算出补全成本。Model Activation Date: 定价适用的起始日期。Match Pattern:用于匹配模型名称和提供方的正则表达式模式。该模式用于匹配运行元数据中ls_model_name的值。Provider:模型提供方。该值用于匹配运行元数据中ls_provider的值。
设置好模型定价映射后,LangSmith 将根据大语言模型调用中提供的 Token 数量,自动计算并汇总各追踪(trace)基于 Token 的费用。
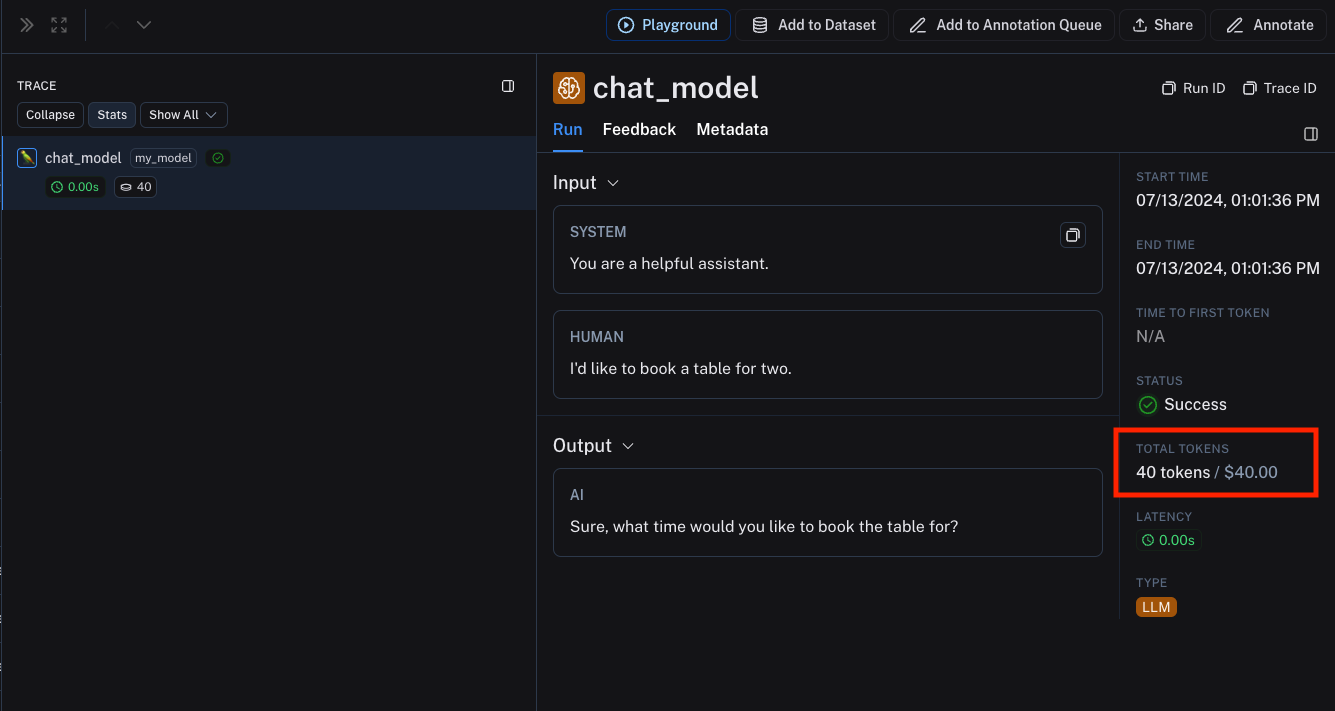
要查看上面的示例实际运行效果,您可以执行以下代码片段:
- Python
- TypeScript
from langsmith import traceable
inputs = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "I'd like to book a table for two."},
]
output = {
"choices": [
{
"message": {
"role": "assistant",
"content": "Sure, what time would you like to book the table for?"
}
}
],
"usage_metadata": {
"input_tokens": 27,
"output_tokens": 13,
"total_tokens": 40,
},
}
@traceable(
run_type="llm",
metadata={"ls_provider": "my_provider", "ls_model_name": "my_model"}
)
def chat_model(messages: list):
return output
chat_model(inputs)
import { traceable } from "langsmith/traceable";
const messages = [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "I'd like to book a table for two." },
];
const output = {
choices: [
{
message: {
role: "assistant",
content: "Sure, what time would you like to book the table for?",
},
},
],
usage_metadata: {
input_tokens: 27,
output_tokens: 13,
total_tokens: 40,
},
};
const chatModel = traceable(
async ({
messages,
}: {
messages: { role: string; content: string }[];
model: string;
}) => {
return output;
},
{ run_type: "llm", name: "chat_model", metadata: { ls_provider: "my_provider", ls_model_name: "my_model" } }
);
await chatModel({ messages });
在上述代码片段中,我们向运行元数据中传入了 ls_provider 和 ls_model_name,以及大语言模型调用的令牌数量。
该信息与我们之前设置的模型定价映射条目相匹配。
生成的追踪信息将包含基于大语言模型调用中提供的令牌数量及模型定价映射条目计算得出的、以令牌为基础的成本。