LangSmith中的警报
自托管版本要求
访问告警功能需要 Helm Chart 版本 0.10.3 或更高版本。
概览
LLM 应用中有效的可观测性需要主动检测故障、性能下降和回归问题。LangSmith 的告警功能有助于识别以下关键问题:
- 模型提供商的API调用频率限制违规
- 您的应用程序延迟增加
- 影响反映终端用户体验的反馈评分的应用变更
LangSmith 中的告警是按项目范围设置的,每个被监控的项目都需要单独配置。
配置警报
步骤 1:导航至创建告警
首先,导航到您希望为其配置告警的 Tracing 项目。点击页面右上角的新建告警(+ New Alert)以设置告警。
步骤 2:选择指标类型
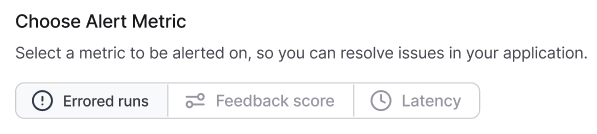
LangSmith 提供基于阈值的三种核心指标告警功能:
| 指标类型 | 描述 | 应用场景 |
|---|---|---|
| Errored Runs | Track runs with an error status | Monitors for failures in an application. |
| Feedback Score | Measures the average feedback score | Track feedback from end users or online evaluation results to alert on regressions. |
| Latency | Measures average run execution time | Tracks the latency of your application to alert on spikes and performance bottlenecks. |
此外,对于出错的运行和运行延迟,您可以定义筛选器来缩小触发告警的运行范围。例如,您可以创建一个错误告警筛选器,用于所有标记为support_agent且遇到RateLimitExceeded错误的llm次运行。
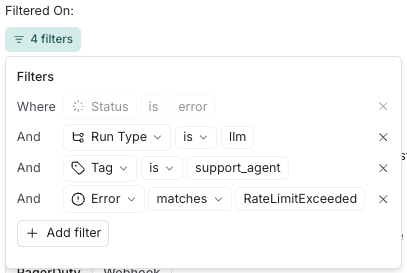
步骤 2:定义告警条件
告警条件由多个组件构成:
- 聚合方法:平均值、百分比或计数
- 比较运算符:
>=、<=或超过阈值 - 阈值:触发警报的数值
- 聚合时间窗口:指标计算的时间周期(当前可选择5分钟或15分钟)
- 反馈键(仅反馈分数提醒):需监控的具体反馈指标

示例:上述配置会在过去5分钟内超过5%的运行出现错误时触发警报。
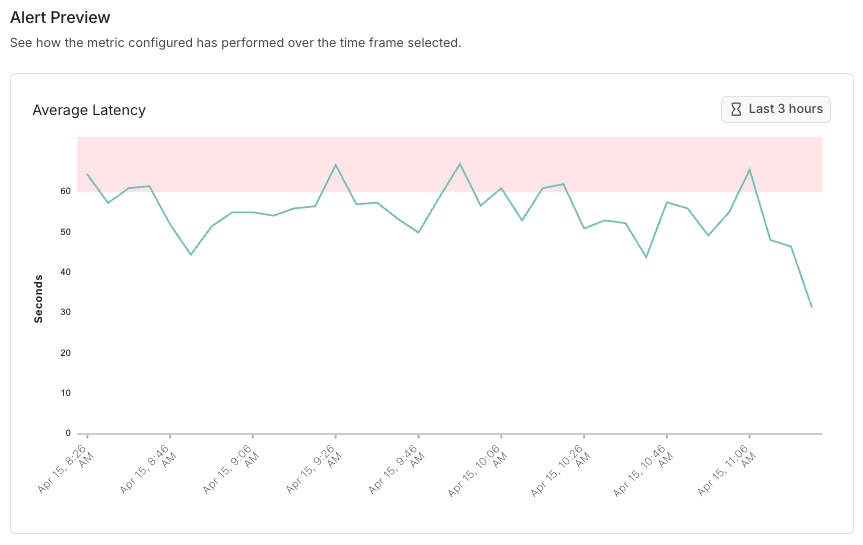
您可以在历史时间窗口内预览告警行为,以了解在选定阈值(以红色标示)下,有多少数据点——以及具体是哪些数据点——会触发告警。例如,为某个项目设置平均延迟阈值为60秒,即可可视化潜在的告警,如下图所示。
步骤 3:配置通知渠道
LangSmith 支持以下通知渠道:
选择合适的渠道,以确保通知能够送达相关团队成员。
最佳实践
- 根据应用的关键性调整敏感度
- 从更宽泛的阈值开始,然后根据观察到的模式进行优化
- 确保告警路由送达合适的待命人员